- Вопрос или проблема
- Примечание
- Ответ или решение
- Понимание результата пост-хок теста Данна после теста Крускала-Уоллиса
- 1. Основы тестирования гипотез
- 2. Может ли схожесть визуально вводить в заблуждение?
- 3. Как работает пост-хок тест Данна?
- 4. Статистическая мощность и размер выборки
- 5. Рекомендации по интерпретации результатов
- Заключение
Вопрос или проблема
Я не понимаю, почему мой пост-хок тест Дунна, после значимого теста Краскала-Уоллиса, обнаруживает значительную разницу между 2022 и 2023 годами, когда они, кажется, имеют наиболее похожее распределение общего изобилия по местам. Я бы подумал, что разница на самом деле должна быть значительной для 2021-2022 и 2021-2023. Можете ли вы это объяснить, пожалуйста?
Мои результаты:
>shapiro.test(summary$Abundance)
data: summary$Abundance
W = 0.49864, p-value = 1.742e-09
>kruskal.test(Abundance ~ Year, data=summary)
data: Abundance by Year
Kruskal-Wallis chi-squared = 9.817, df = 2, p-value = 0.007384
>dunnTest(summary$Abundance, summary$Year, method="bonferroni")
Comparison Z P.unadj P.adj
1 2021 - 2022 -0.8256766 0.408987553 1.00000000
2 2021 - 2023 2.2707925 0.023159544 0.06947863
3 2022 - 2023 2.8414068 0.004491497 0.01347449 # Как??
Вот моя таблица данных. Столбец Abundance – это количество индивидуумов, собранных на каждом участке.
> dput(summary)
structure(list(Genus = c("Ceratina", "Ceratina", "Ceratina",
"Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina",
"Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina",
"Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina",
"Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina",
"Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina", "Ceratina"
), Sex = c("M", "M", "M", "M", "M", "M", "M", "M", "M", "M",
"M", "M", "M", "M", "M", "M", "M", "M", "M", "M", "M", "M", "M",
"M", "M", "M", "M", "M", "M", "M", "M", "M", "M"), Year = structure(c(1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L
), levels = c("2021", "2022", "2023"), class = "factor"), SiteID = structure(c(1L,
3L, 8L, 10L, 13L, 17L, 18L, 23L, 25L, 27L, 28L, 3L, 8L, 13L,
17L, 18L, 19L, 27L, 1L, 3L, 6L, 12L, 13L, 17L, 18L, 19L, 20L,
22L, 23L, 24L, 25L, 26L, 27L), levels = c("H02", "H03", "H04",
"H05", "H06", "H07", "H08", "H09", "L01", "L02", "L04", "L05",
"L06", "L07", "L08", "L09", "L10", "L12", "M01", "M02", "M03",
"M04", "M05", "M06", "M08", "M09", "M10", "M11", "M12"), class = "factor"),
ITD.avg = c(1.089, 1.155, 1.199, 1.32, 1.21, 1.17203225806452,
1.3695, 1.188, 1.089, 1.1913, 1.111, 1.21025, 1.3068125,
1.17591666666667, 1.3081, 1.27319444444444, 1.17591666666667,
1.326125, 1.245, 1.162, 1.1952, 1.2948, 1.2948, 1.23788571428571,
1.245, 1.1205, 1.1205, 1.245, 1.0458, 1.2699, 1.1703, 1.245,
1.245), WW.Avg = c(0.666666666666667, 2, 1, 0, 3.33333333333333,
0.709677419354839, 0, 0, 2, 3.9, 0, 1.75, 0.25, 1.5, 0.95,
1.16666666666667, 1.33333333333333, 3, 1, 2.16666666666667,
4, 5, 4.5, 2.07142857142857, 0.75, 5, 3.25, 2, 1.5, 3, 3.5,
1, 4), Abundance = c(3, 2, 3, 1, 6, 31, 2, 1, 2, 10, 3, 2,
4, 3, 10, 9, 3, 2, 1, 3, 1, 1, 1, 7, 2, 2, 2, 1, 1, 2, 2,
1, 1)), class = c("grouped_df", "tbl_df", "tbl", "data.frame"
), row.names = c(NA, -33L), groups = structure(list(Genus = c("Ceratina",
"Ceratina", "Ceratina"), Sex = c("M", "M", "M"), Year = structure(1:3, levels = c("2021",
"2022", "2023"), class = "factor"), .rows = structure(list(1:11,
12:18, 19:33), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, -3L), .drop = TRUE, class = c("tbl_df",
"tbl", "data.frame")))
И если я нарисую распределение общего изобилия по участкам за годы, 2022 и 2023 выглядят наиболее похожими…

Вас вводят в заблуждение графики для сравнения яблок и апельсинов. Если вы хотите визуально понять различия между годами, если таковые существуют, используйте блочный график с усами.
library(ggplot2)
ggplot(summ, aes(Year, Abundance)) +
geom_boxplot() +
theme_bw()
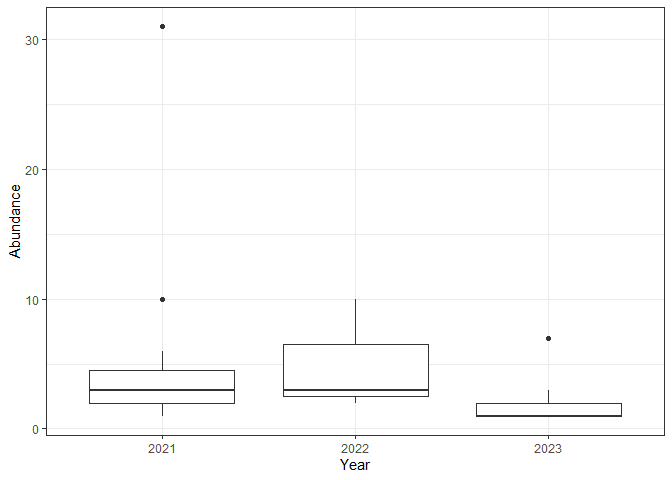
Создано 30 октября 2024 года с помощью reprex v2.1.1
Похоже, что 2023 год, в среднем, отличается. Вы теперь можете протестировать это с помощью ANOVA или его непараметрического эквивалента, теста Краскала-Уоллиса.
Тест Краскала-Уоллиса на изобилие по годам ниже показывает значительную разницу в группах по годам, поэтому можно применить пост-хок тест Дунна.
kruskal.test(Abundance ~ Year, summ)
#>
#> Тест ранговой суммы Краскала-Уоллиса
#>
#> data: Abundance by Year
#> Kruskal-Wallis chi-squared = 9.817, df = 2, p-value = 0.007384
FSA::dunnTest(Abundance ~ Year, summ)
#> Дунн (1964) множественное сравнение Краскала-Уоллиса
#> p-значения откорректированы методом Холма.
#> Сравнение Z P.unadj P.adj
#> 1 2021 - 2022 -0.8256766 0.408987553 0.40898755
#> 2 2021 - 2023 2.2707925 0.023159544 0.04631909
#> 3 2022 - 2023 2.8414068 0.004491497 0.01347449
Создано 30 октября 2024 года с помощью reprex v2.1.1
Примечание
Это случай, когда я предпочитаю базовую графику. Это намного проще – одна строка кода, без необходимости загружать дополнительный пакет.
boxplot(Abundance ~ Year, summ)
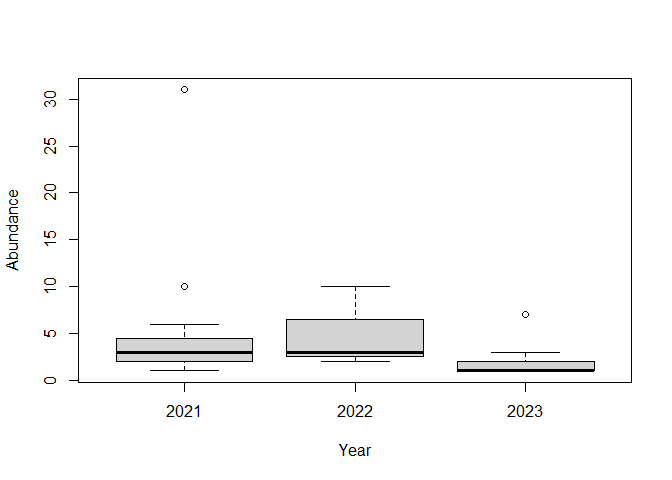
Создано 30 октября 2024 года с помощью reprex v2.1.1
Ответ или решение
Понимание результата пост-хок теста Данна после теста Крускала-Уоллиса
Ваша ситуация, в которой пост-хок тест Данна выявляет значимые различия между годами 2022 и 2023, несмотря на визуально схожую распределенность данных, ставит перед нами несколько интересных вопросов. Давайте разберем, почему это может происходить.
1. Основы тестирования гипотез
Пост-хок тест Данна применяется для дальнейшего исследования результатов теста Крускала-Уоллиса. Когда тест Крускала-Уоллиса показывает статистически значимые различия между группами (в данном случае – годами), это свидетельствует о том, что хотя бы одна пара групп отличается. Однако не указывает, какая именно пара имеет различия. Именно здесь на помощь приходит пост-хок тест.
2. Может ли схожесть визуально вводить в заблуждение?
Как вы упомянули, на графике доступного распределения общая абунданция по годам 2022 и 2023 выглядит очень схожей. Однако визуальное восприятие не всегда является надежным показателем статистической значимости. Это связано с следующими факторами:
- Изменчивость данных. Коэффициент изменчивости в ваших данных может быть разным. Например, если в 2022 году устанавливается богатая популяция с небольшими колебаниями, а в 2023 – также, но с большей изменчивостью, это может привести к значительным различиям в тестах, даже если медианы близки.
- Влияние выбросов. В вашем наборе данных могут быть выбросы, которые в значительной степени влияют на результаты тестов статистики. Они могут увеличивать Z-значение для каких-либо пар, несмотря на визуальные схожести.
3. Как работает пост-хок тест Данна?
Пост-хок тест Данна оценивает каждую пару групп (парные сравнения) с учетом общей выборки, что добавляет уровень сложности. Например:
- Сравнение 2021 и 2022: значений насчитывается по всей базе данных, и возможно, в этой паре имеется высокая степень перекрытия с медиа и вариацией, что приводит к незначительным значениям Z и p.
- Сравнение 2022 и 2023: наоборот, если данные в 2023 году имеют более широкий диапазон, это может подтолкнуть к выявлению значимости при отсутствии визуальных доказательств.
4. Статистическая мощность и размер выборки
Размер вашей выборки может также влиять на результаты. При малом размере выборки более вероятно обнаружение статистически значимых различий, даже если они не заметны визуально. Тесты с малым числом наблюдений более чувствительны к изменениям.
5. Рекомендации по интерпретации результатов
- Используйте дополнительные визуализации, такие как ящики с усами (boxplot), для лучшего понимания распределения данных. Это может помочь оценить медианные значения и изменчивость наглядно.
- Учитывайте не только p-значения, но и другие статистические метрики, такие как Z-значения и размеры эффектов, для более полного понимания различий.
- Следует также помнить о методах коррекции при множественных сравнениях, таких как метод Бонферрони, который вы уже используете.
Заключение
Разница в результатах тестов между схожими на первый взгляд годами может быть интригующей, но она подчеркивает важность применения комплексного подхода к статистическому анализу. Ваша задача на следующем этапе — проанализировать данные глубже, прежде чем делать окончательные выводы о различиях между группами.