Вопрос или проблема
Я относительно новичок в машинном обучении, и любые предложения и исправления кода будут большой помощью.
Я использую Lasso для отбора признаков и хочу выбрать лямбда, которая обеспечивает наименьшую ошибку. Используемый мной набор данных содержит 500 образцов и является несбалансированным. Мне нужны предложения по установке диапазона значений лямбда и определению количества лямбда, которые нужно сгенерировать для кросс-валидации.
В основном у меня есть два момента беспокойства:
1. Если изменить диапазон значений лямбда, минимальное и максимальное значения лямбда, то я получаю разные оптимальные лямбда и соответствующее MSE. Даже если разница очень мала, значение оптимального лямбда меняется в зависимости от заданного диапазона поиска для лямбда, так как же мне определить диапазон?
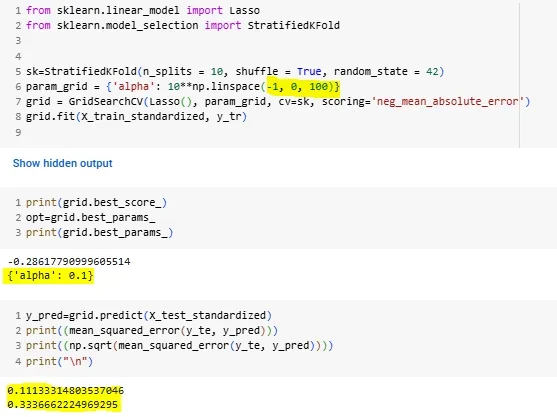
рис-1: Изменение диапазона лямбда и количества лямбда для генерации для кросс-валидации
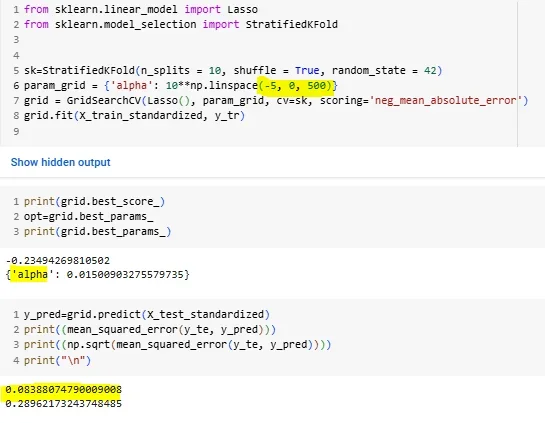
рис-2: Изменение диапазона лямбда и количества лямбда для генерации для кросс-валидации
2. Если я работаю с фиксированным диапазоном лямбда и варьирую количество лямбда для генерации в пределах фиксированного диапазона для проведения кросс-валидации, то я получаю разные оптимальные лямбда и соответствующее MSE.
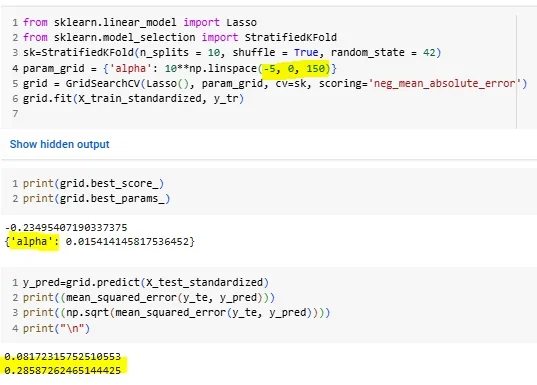
рис-3: изменение количества лямбда для кросс-валидации
Так как же мне определить диапазон поиска? Какова лучшая практика? Пожалуйста, дайте мне некоторые рекомендации. Заранее спасибо.
Ответ или решение
Советы по кросс-валидации для выбора оптимального λ в Lasso
Используя Lasso для отбора признаков, вы стремитесь минимизировать среднюю квадратичную ошибку (MSE), выбирая оптимальное значение параметра регуляризации λ. Давайте разберёмся в ваших вопросах и предложим надёжные стратегии для работы с этим методом.
1. Определение диапазона λ
Первым важным аспектом является выбор диапазона значений λ. Основная концепция заключается в том, что λ контролирует тяжесть штрафа за сложность модели, и в процессе кросс-валидации вы стремитесь найти компромисс между bias и variance. Вот шаги для настройки диапазона:
-
Начальная настройка: Логарифмическое масштабирование λ часто помогает, поскольку значения λ могут сильно варьироваться. Попробуйте диапазон от 0.0001 до 10 (или даже больше), используя логарифмическую шкалу, например, через
np.logspace(-4, 1, num=100)в Python. -
Анализ начальных результатов: Запустите предварительное тестирование модели, чтобы получить представление о том, как λ влияет на MSE. Проанализируйте значения, при которых ошибка начинает выравниваться или увеличиваться.
-
Уточнение диапазона: На основании первых результатов вы можете уточнить диапазон, остановившись на более узком интервале, если это необходимо. Например, если вы заметили, что оптимальное значение λ находится в пределах от 0.1 до 1, вы можете изменить диапазон на что-то вроде
np.logspace(-1, 0, num=50)и продолжить.
2. Установка количества λ для кросс-валидации
Количество λ, которое вы выбираете, также может влиять на результаты кросс-валидации. Вариации в количестве λ между фиксированными границами могут приводить к различиям в среднем звене и MSE по следующим причинами:
-
Постепенное исследование: Увеличивайте количество λ в вашей сетке. Например, начинайте с 50 значений, чтобы получить первое представление о поведении модели, и постепенно повышайте до 100 или 200, если необходимо.
-
Сеточная или случайная кросс-валидация: Дополнительные подборы λ могут быть оправданы сеточной или случайной кросс-валидацией, что даст вам более детальное представление о градиенте MSE по значениям λ.
-
Использование
GridSearchCVилиRandomizedSearchCV: Эти инструменты вscikit-learnпозволят вам автоматически исследовать различные значения и выбирать оптимальное значение λ на основе кросс-валидации.
3. Понимание изменений в оптимальном λ
Существует множество факторов, которые могут влиять на оптимальное значение λ и MSE:
-
Индивидуальные особенности данных: Поскольку ваш набор данных содержит 500 примеров и является несбалансированным, важно тщательно оценить, как различные значения λ могут взаимодействовать с вашим набором данных. Убедитесь, что вы используете подходящие метрики для оценки модели, такие как F1-score или AUC, которые лучше отражают производительность на несбалансированных данных.
-
Переобучение и недообучение: Всегда стоит проверять, не оказывается ли ваша модель переобученной из-за выбора слишком низких значений λ. Анализируйте как тренировочную, так и тестовую ошибки при различных λ.
Заключение
Учёт этих рекомендаций поможет вам более эффективно устанавливать диапазоны и количество параметров λ для кросс-валидации в Lasso. Начните с логарифмичного масштабирования и расширяйте или сужайте диапазон на основе предварительных результатов. Четкая интерпретация графиков и постоянный анализ помогут вам найти сбалансированное значение λ, удовлетворяющее критериям качества модели.
Если у вас есть ещё вопросы или вам необходима помощь с кодом и реализацией, не стесняйтесь обращаться за дополнительной помощью. Успехов в вашем обучении и исследованиях в области машинного обучения!