Вопрос или проблема
У меня есть тысяча рукописных ответов на следующую бумажную форму:
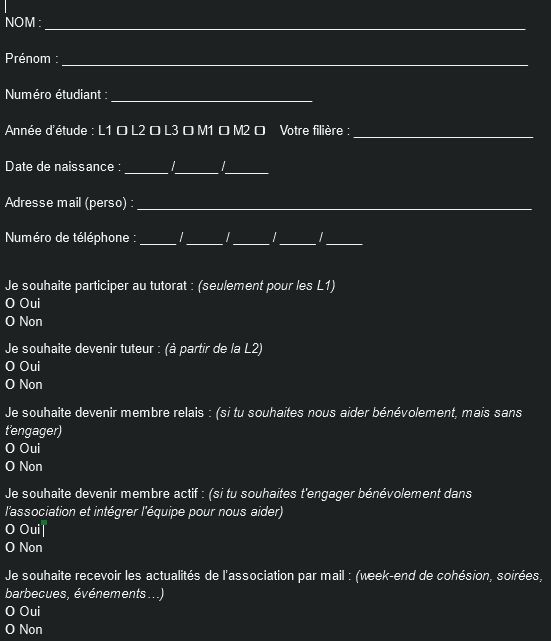
Мне нужно их отсканировать (у меня есть сканер) и экспортировать все данные в таблицу, похожую на эту:
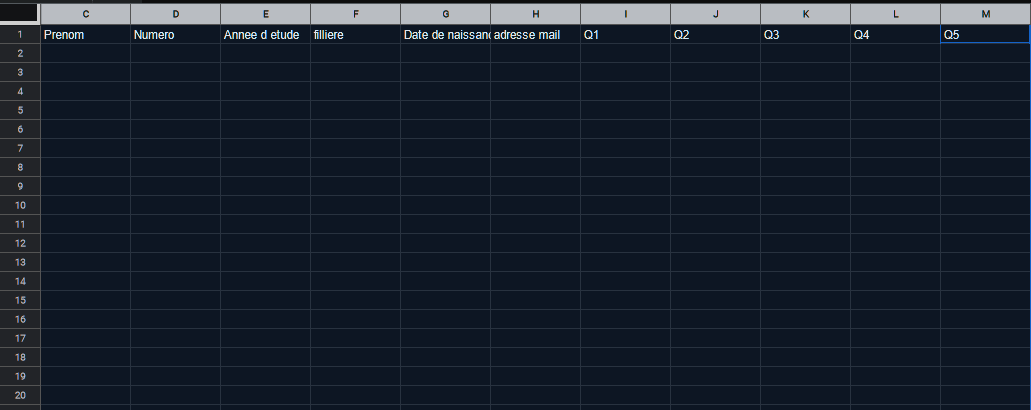
Это возможно? С помощью OCR? С использованием LATEX? С помощью Python? С программным обеспечением для Windows? Я открыт для всех ответов. Нет проблемы, если документ нужно преобразовать, и, например, текстовые поля будут большими ящиками или нужно будет писать буквы заглавными буквами.
Вы можете обнаружить множество программ OCR (оптическое распознавание символов), которые будут выполнять задачи, которые вы требуете. Я использовал поисковый запрос “ocr form scanning” (который можно улучшить), и было получено множество результатов.
Одним из них является продукт Amazon Web Services под названием Textract, который явно описывает вашу задачу:
Amazon Textract — это сервис машинного обучения (ML), который автоматически
извлекает текст, рукописный текст и данные из отсканированных документов. Он выходит
за пределы простого оптического распознавания символов (OCR), чтобы идентифицировать,
понимать и извлекать данные из форм и таблиц. В настоящее время многие
компании вручную извлекают данные из отсканированных документов, таких как PDF,
изображения, таблицы и формы, или с помощью простого программного обеспечения OCR, которое
требует ручной настройки (которая часто должна быть обновлена, когда
форма изменяется). Чтобы преодолеть эти ручные и дорогие процессы,
Textract использует ML для чтения и обработки любого типа документа, точно
извлекая текст, рукописный текст, таблицы и другие данные без ручных
усилий. Вы можете быстро автоматизировать обработку документов и действовать на основе
извлеченной информации, независимо от того, автоматизируете ли вы обработку кредитов или
извлекаете информацию из счетов и квитанций. Textract может
извлекать данные за считанные минуты, а не часы или дни. Кроме того,
вы можете добавить человеческие обзоры с помощью Amazon Augmented AI для
контроля за вашими моделями и проверки конфиденциальных данных.
Это может не быть единственным ответом на вашу цель, но это показывает, что ресурсы доступны и могут быть найдены с помощью соответствующих поисковых запросов.
Ответ или решение
Сканирование и экспортирование данных с бумажных форм — задача, с которой сталкивается множество организаций. В вашем случае, где имеется тысяча рукописных ответов, необходимо разумно подойти к решению этой проблемы. Хочу предложить поэтапный план действий, учитывая современные технологии распознавания текста и автоматизации обработки данных.
1. Подготовка к сканированию
Перед тем как приступить к сканированию, важно убедиться, что каждая форма чистая и аккуратная. Проверьте, чтобы на документах не было помех, таких как чернила, размытости или повреждения. Хорошее качество сканирования особенно критично для OCR-технологий.
2. Сканирование документов
Используйте качественный сканер, который позволяет выполнять задания в высоком разрешении (300 dpi и выше). Это обеспечивает более точное распознавание текста. Сканируйте формы в форматах PNG или TIFF, так как они лучше сохраняют качество изображений по сравнению с JPEG.
3. Использование OCR для извлечения данных
Для автоматизированного извлечения данных из ваших сканов можно использовать решения на основе OCR (Оптического распознавания символов). Вот несколько наиболее популярных и эффективных опций:
-
Amazon Textract: Этот облачный сервис от Amazon позволяет не только распознавать текст, но и извлекать данные из таблиц и форм. Он использует машинное обучение для автоматической обработки документов, что значительно упрощает задачу.
-
Google Vision API: Альтернативное решение, предоставляющее инструменты для синтаксического анализа изображений с дополнительной поддержкой множества языков и форматов.
-
Tesseract: Это бесплатный проект с открытым исходным кодом, который позволяет выполнять OCR с помощью библиотеки Python. Для использования Tesseract потребуется некоторая настройка, но он может быть очень эффективным.
4. Постобработка данных
После извлечения данных с помощью OCR важно произвести проверку и верификацию полученных результатов. Рукописный текст может иногда содержать ошибки, поэтому лучше всего вручную просмотреть наиболее критичные данные.
5. Экспорт данных в таблицу
После успешного извлечения и проверки данных, можно экспортировать результаты в электронные таблицы, такие как Microsoft Excel или Google Sheets. В случае с Amazon Textract, данные могут быть экспортированы напрямую в формате CSV, что упрощает импорт в таблицы.
6. Автоматизация процесса с помощью Python
Если вы хотите создать полностью автоматизированный процесс, можно написать скрипт на Python, который будет:
- Сканировать документы: Автоматизированное сканирование с помощью библиотек, таких как
pyautoguiилиscanimage. - Применять OCR: Использовать
Pytesseractдля обработки отсканированных изображений. - Сохранять результаты в CSV: Использовать
pandasдля формата данных и экспорта в .csv или .xlsx.
Заключение
Современные технологии распознавания текста и машинного обучения открывают множество возможностей для автоматизации обработки бумажной документации. С учетом вышеуказанных шагов вы сможете эффективно сканировать, распознавать и экспортировать данные из ваших форм в удобный для анализа формат. Поэтому не стоит удивляться, что все эти задачи выполнимы в разумные сроки с высоким уровнем точности.