Вопрос или проблема
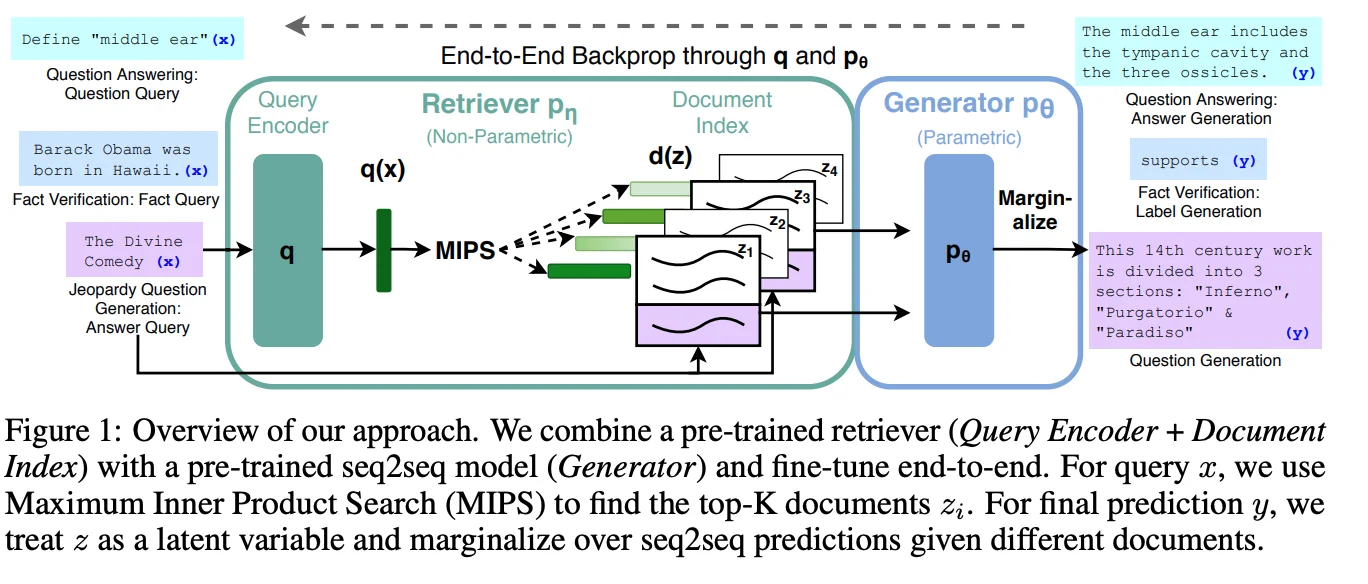
Архитектура RAG из оригинальной статьи
Поскольку потеря рассчитывается на выходном слое генератора, как градиенты обратным распространением передаются в модель извлечения?
Потому что вводом для генератора является чистый текст, то есть текст извлеченного документа + вопрос.
Указано, что вся архитектура настраивается в режиме end-to-end. Обратите внимание на рисунок “end-to-end backprop through q”, где q — это кодировщик запроса. Мой вопрос: как ошибка обратно пропагируется к q? Потому что при расчете потерь на выходе генератора модель кодировщика запроса не играет никакой роли.
Статья ясно заявила, что
Извлекатель (DPR) предоставляет латентные документы, основанные на
входных данных, а модель seq2seq (BART [32]) затем основывается на этих
латентных документах вместе с входными данными для генерации выхода.
Таким образом, было очевидно, что генератор принимает текст (идентификаторы ввода) в качестве входных данных. Но тогда возникает вопрос: “как градиенты распространяются до модели кодировщика запроса?”
Мне пришлось просмотреть исходный код проекта RAG на huggingface, чтобы найти ответ на этот вопрос.
Я начал с класса RagModel. Изучив исходный код этого класса, я заметил, что модель генератора действительно использовала input_ids в функции forward.
Чтобы найти, как градиенты обратно пропагируются до кодировщика запроса, нам нужно выяснить, как рассчитываются потери. Мы видим, что используется варьируемая версия потерь nll (строка 864).
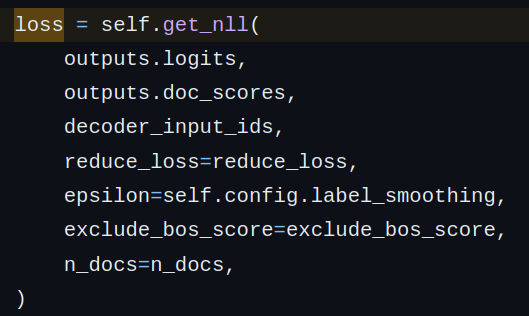
Поскольку кодировщик запроса участвует только благодаря doc_scores, мы будем следовать за ним. Проанализировав функции (get_nll –> marginalize), мы обнаружили, что log-softmax применяется к (a) логиту последовательности генератора и (b) doc_scores.

Затем обе эти величины складываются и передаются через трюк логармированный суммы экспонент. Почему лог-сумма-экспонена? Я думаю, это потому, что это будет эквивалентно суммированию вероятностей ($\sum_{i}{e^{log(p_i)}} = \sum_{i}{p_i}$) и взятию логарифма (для численной стабильности). Таким образом, градиенты обратно пропагируются до модели кодировщика запроса.
Поскольку у модели кодировщика запроса нет истинных значений, потери извлечения просто вычисляются как softmax от doc_scores. Мне кажется, что когда эта потеря извлечения добавляется к LM-потере (seq_logits), то результирующая потеря в основном представляет собой следующую философию:
“если окончательный сгенерированный ответ достаточно хорош (низкая LM потеря), то это
указывает на то, что извлеченные документы также были достаточно хороши. Следовательно,
хорошая репрезентация запроса! Нет необходимости в больших изменениях в кодировщике запроса.
Аналогично, большая LM потеря –> плохие извлеченные документы –> нужны большие изменения
(обновления параметров) в кодировщике запроса.”
Ответ или решение
Вопрос о том, как модель извлечения (Query Encoder) обучается в конечной системе Retrieval Augmented Generation (RAG) через обратное распространение градиентов, представляет собой интересную задачу, помимо самой архитектуры и процессов, которые происходят в ней. Давайте разберем ключевые аспекты этого процесса.
Архитектура RAG
Архитектура RAG, как указано в оригинальной статье, включает два ключевых компонента: модель извлечения (например, Dense Passage Retrieval – DPR) и генератор (например, BART). Модель извлечения предоставляет набор документов, соответствующих заданному запросу, на основе которого генератор затем формирует ответ.
Обратное распространение градиентов
При обучении сети в RAG важным моментом является способ расчета потерь (loss) и того, как градиенты успевают вернуться к модели извлечения. Потеря рассчитывается на выходном слое генератора, однако модель извлечения (Query Encoder) также участвует в этом процессе. По сути, родственные комитеты RAG утверждают, что архитектура обучается end-to-end, что подразумевает, что все компоненты испытывают сложный процесс обратного распространения.
Расчет потери
Как вы правильно заметили, модель извлечения вносит свой вклад в расчет потери через doc_scores, которые зависят от выходных данных модели извлечения. При помощи функции get_nll и marginalize создается лог-функция потерь, которая сочетает активность генератора и выходные документы, предоставленные моделью извлечения.
-
log-softmax — эта функция применяется как к логитам генератора, так и к doc_scores. Это позволяет создать совместное распределение, акцентируя внимание на том, как качество документов влияет на качество генерации.
-
Затем используется метод log-sum-exp, который обеспечивает числовую стабильность и позволяет суммировать вероятности, что критически важно для оптимизации.
Как градиенты достигают Query Encoder
Градиенты достигают Query Encoder благодаря тому, что как потери генератора, так и потери извлечения (от softmax doc_scores) требуют обратного распространения. Объединив эти два аспекта, мы способны передать информацию обратно в Query Encoder.
Объяснение через философию потери
Важно отметить, что модель извлечения не имеет прямой "истинной" метки, но мы можем выражать потери через doc_scores. Это производит интуитивное представление, где низкая потеря генерации (LM loss) указывает на то, что документы были уместными. В то время как высокая потеря указывает на необходимость значительного изменения в Query Encoder, подчеркивая, что извлеченные документы нуждаются в улучшении.
Так, конечная утрированная интерпретация потерь подсказывает, что "если сгенерированный ответ хорош (низкая LM loss), то документы соответствуют запросу, следовательно, вероятность успешного паттерна запроса велика".
Заключение
Таким образом, модель извлечения в системе RAG действительно обучается конечным образом, так как градиенты от функции потерь генератора в конечном итоге возвращаются к Query Encoder, обогатив процесс обучения. Этот механизм позволяет как улучшать качество извлечения, так и качество генерации, что делает подход RAG особенно эффективным для задач, связанных с извлечением информации и генерацией текста.
Эффективность этого процесса подчеркивается необходимостью интеграции информации из различных источников, что и является сердцем мощного инструмента RAG.