Вопрос или проблема
Я экспериментирую с фреймворком кластеризации и предсказания оттока, cluschurn, который был развернут в производственной среде в Snap, Inc. В их исследовательской работе paper_link они используют 14 дней данных пользователей и рассматривают их как временной ряд. Они проводят некоторые преобразования и получают 3-мерный набор данных размером 12x14xm пользователей; каждый пользователь, m, имеет 12 ежедневных признаков за 14 дней. Этот набор передается в LSTM, так что каждый временной шаг LSTM получает 12-мерный вектор. Надеюсь, я сформулировал это правильно, чтобы это было понятно. Они смогли улучшить свои результаты, добавив слой эмбеддинга между входом и слоем LSTM.
Мы соединяем полносвязную прямую нейронную сеть с исходными векторами ежедневной активности, которые преобразуют разреженные активностные признаки пользователей каждого дня в распределительные эмбеддинги активности…

Я совершенно запутался в том, как это выглядит с точки зрения размерности, и не понимаю, есть ли полносвязная сеть перед каждым временным шагом LSTM или одна полносвязная сеть перед подачей в LSTM? Например, сглаживается ли 3-мерный набор данных, а затем подается в полносвязную сеть, которая потом снова преобразует его в 3-мерный набор данных с 14 временными шагами?
Я создал эти концепты, чтобы прояснить, что я имею в виду.
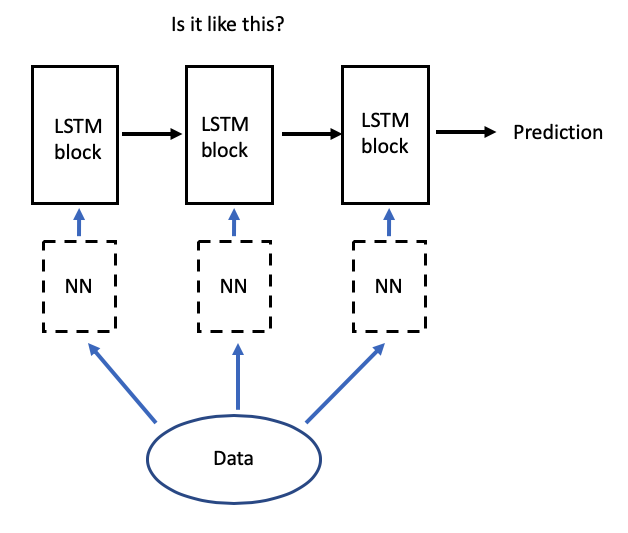
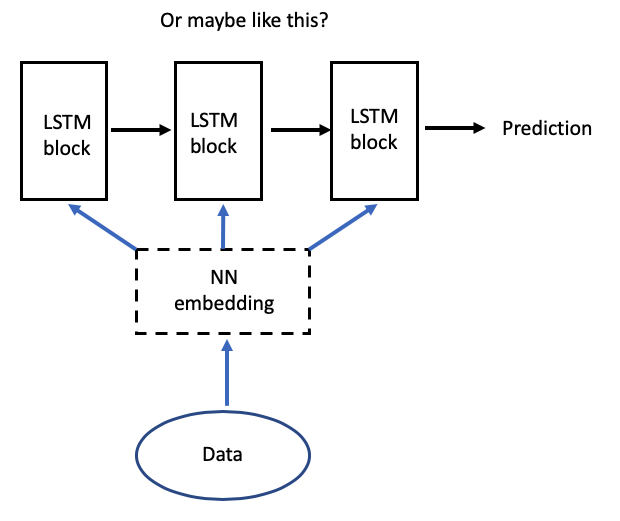
Самый простой способ понять их предложение — взглянуть на их исходный код, который связанный со статьей: https://github.com/yangji9181/ClusChurn/blob/master/model.py#L35
Это показывает, что “эмбеддинг” получается с помощью простой линейной сети.
Ответ или решение
Вопрос о внедрении слоя эмбеддинга перед слоем LSTM в нейронных сетях является актуальным и требует внимательного рассмотрения структуры данных и процесса обработки. Давайте разберем, как это может работать на примере вашего описания системы «ClusChurn», используемой в Snap, Inc.
1. Структура исходных данных
Вы упомянули, что ваши данные представляют собой трехмерный массив размером 12x14xm, где:
- 12 — количество признаков (фичей),
- 14 — временные шаги (дни),
- m — количество пользователей.
Это значит, что для каждого пользователя за 14 дней наблюдаются 12 различных признаков его активности.
2. Слой эмбеддинга
Слой эмбеддинга предназначен для преобразования входных разреженных векторов признаков в более плотные векторы фиксированной размерности. Это позволяет сети лучше захватывать скрытые зависимости и связи между признаками. В вашем случае применен слой линейной регрессии, который может быть интерпретирован как слой эмбеддинга.
3. Техническая реализация
Теперь стоит разобраться в вопросе, как именно происходит преобразование данных. Часто встречаются два подхода:
Подход 1: Эмбеддинг для каждого временного шага
В этом подходе каждый временной шаг (каждый день) обрабатывается отдельно. Это значит, что каждый из 12 признаков для каждого дня подается на вход одному и тому же слою эмбеддинга, который преобразует 12-димнсионный вектор в более компактный вектор фиксированной размерности, скажем, n. После этого полученные векторы для всех 14 дней формируют новую 3D-матрицу:
- Размерность: 14x(n)x(m), где n — размерность эмбеддингового пространства.
Затем эта новая матрица вводится в LSTM слой. Это дает LSTM возможность обрабатывать изменяющиеся во времени эмбеддинги пользователей.
Подход 2: Полносвязная сеть перед LSTM
Второй подход подразумевает использование полной связной нейронной сети, которая обрабатывает входные данные (размерности 12x14xm) и формирует усредненный или представительный вектор для всего промежутка данных. Вы можете применить слой с несколькими нейронами, который принимает на вход 12 признаков для каждого дня и агрегирует их, после чего формирует выходной 1D-вектор, который будет подаваться в LSTM.
Однако в данном случае структура данных должна быть также адаптирована: входные данные могут быть как-то сгруппированы, чтобы соответствовать ожидаемым размерностям LSTM, что может усложнить логику и настройки.
4. Результаты и выводы
Упрощение преобразований за счет слоя эмбеддинга между признаками входных данных и LSTM существенно улучшает качество предсказаний и clustering результатов, точно так же, как это показано в статье. Слой эмбеддинга обеспечивает преобразование признаков в пространство, которое лучше подходит для дальнейшего анализа, позволяя LSTM лучше захватывать временные паттерны, что и позволяет повысить точность предсказаний.
Заключение
Таким образом, правильное понимание и внедрение слоя эмбеддинга перед LSTM является ключевым для достижения высоких результатов в анализе временных рядов, таких как в задаче прогнозирования оттока пользователей. Рекомендуется проанализировать исходный код на GitHub для лучшего понимания реализации выбранного подхода и проведения экспериментов с различными архитектурами для оптимизации результатов вашей модели.