Вопрос или проблема
Я новичок в обработке естественного языка и хотел бы спросить, как я могу извлечь предложения из текста на основе ключевых слов, которые у меня есть, используя Python. Я создал список ключевых слов, которые будут использоваться для извлечения предложений из документа.
Если это будет простая задача токенизации, при которой вы будете перебирать список через токены, как я могу захватить синонимы или связанные слова?
Например:
Ключевое слово: Внутренний бизнес
Предложение: Вы можете использовать это программное обеспечение только для вашего бизнеса.
Ключевое слово: Конфиденциальность
Предложение: Информация будет храниться в максимально защищенном виде.
На самом деле я реализовал категоризацию текста с помощью TF-IDF, но с небольшим набором данных и большим количеством ключевых слов. Я не думаю, что это сработает. Спасибо заранее.
Возможно ли использовать предварительно обученные модели, такие как word2vec?
Также возможно ли создать пользовательскую модель, которая будет соответствовать моим потребностям?
Идеальный способ получить связанные предложения – попробовать получить вектор предложения для предложений, которые вы хотите категоризировать, а затем сравнить векторы ваших заранее определенных ключевых слов с полученными векторами предложений. Вы можете получить векторы предложений, просто усреднив векторы слов слов, присутствующих в предложениях. Как только векторы предложений получены, вы можете использовать косинусное сходство для сравнения векторов ключевых слов и векторов предложений. Тот, у которого максимальное косинусное сходство, даст вам результат.
Одним из вариантов является расстояние между словами (WMD), алгоритм для нахождения расстояния между парами строк. Он основан на векторных представлениях слов (например, word2vec), которые кодируют семантическое значение слов в плотные векторы.
Расстояние WMD измеряет несходство между двумя текстовыми документами как минимальное количество расстояния, которое вложенные слова одного документа должны “пройти”, чтобы достичь вложенных слов другого документа.
Например:
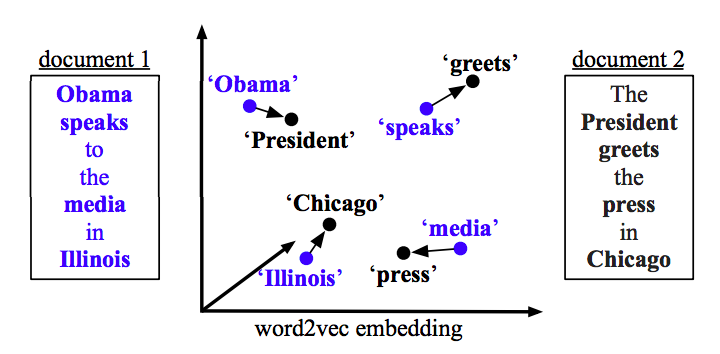
Источник: “От векторных представлений слов к расстояниям документов” Статья
В вашем случае вы возьмете ваше ключевое слово(а) и сравните его с каждым предложением. Если расстояние ниже порога, ключевое слово(а) связано с предложением.
Ответ или решение
Чтобы эффективно извлекать предложения из документов на основе заданного списка ключевых слов с использованием Python, необходимо учесть несколько важных аспектов.
1. Понимание задачи
Цель заключается в том, чтобы извлекать предложения, содержащие ключевые слова, и при этом учитывать синонимы и родственные слова этих ключевых слов. Это связано с тем, что простой подход на основе токенизации может оказаться недостаточным.
2. Подходы к решению
2.1 Использование векторных представлений слов
Одним из наиболее распространённых методов для достижения этой цели является использование моделей векторного представления слов, таких как Word2Vec или GloVe. Эти модели преобразуют слова в плотные векторные представления, позволяя «улавливать» семантические связи между ними.
- Word2Vec: Это модель, которая обучается на большом корпусе текста, превращая слова в векторы в пространстве. Слова с похожим значением будут близки друг к другу в этом пространстве.
- GloVe: Это также предобученная модель, которая использует статистическое представление корелляций между словами в контексте документа.
2.2 Создание векторов предложений
Для извлечения предложений, соответствующих ключевым словам, можно использовать следующее:
- Токенизация документа на предложения и слова.
- Выделение векторов для каждого слова в предложении с помощью выбранной модели (например, Word2Vec).
- Расчёт вектора предложения путём усреднения векторов всех слов в предложении.
- Создание векторов для ключевых слов.
2.3 Сравнение векторов
Теперь, когда у нас есть векторы для предложений и ключевых слов, можно использовать косинусное сходство для сравнения векторов:
- Косинусное сходство: Этот метод позволяет определить, насколько два вектора являются «похожими» по направлению. Формула для вычисления выглядит так:
[
\text{cosine similarity}(A, B) = \frac{A \cdot B}{|A| |B|}
]
где (A) и (B) — векторы.
3. Пример реализации
Вот пример кода, который демонстрирует, как реализовать вышеуказанные шаги с использованием библиотеки gensim для работы с Word2Vec.
import gensim.downloader as api
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Загружаем модель Word2Vec
model = api.load('word2vec-google-news-300')
def get_sentence_vector(sentence):
words = sentence.split()
words = [word for word in words if word in model.vocab]
if not words:
return np.zeros(model.vector_size)
return np.mean(model[words], axis=0)
def extract_sentences(keywords, document):
sentences = document.split('.')
keyword_vectors = [get_sentence_vector(keyword) for keyword in keywords]
extracted_sentences = []
for sentence in sentences:
sentence_vector = get_sentence_vector(sentence)
if any(cosine_similarity([sentence_vector], [kw_vector])[0][0] > 0.5 for kw_vector in keyword_vectors):
extracted_sentences.append(sentence.strip())
return extracted_sentences
# Пример использования
keywords = ["Internal business", "Confidentiality"]
document = "You can only use this software for your business only. Information will be kept as secure as possible."
result = extract_sentences(keywords, document)
print("Extracted Sentences:")
print(result)4. Варианты улучшения
- Word Mover’s Distance (WMD): Это более сложный метод, который вычисляет расстояние между текстами в векторном пространстве. WMD можно рассматривать как расширение косинусного сходства с учётом семантической близости слов.
- Тонкая настройка модели: Если стандартные предобученные модели не удовлетворяют вашим требованиям, вы можете обучить собственную модель на специфику вашего текста.
Заключение
Использование предобученных моделей векторизации слов, таких как Word2Vec, в сочетании с косинусным сходством, предоставляет мощный инструмент для извлечения предложений на основе ключевых слов и их синонимов. Выбор подхода зависит от ваших потребностей и сложности вашего проекта. Совместив различные методы, вы сможете значительно улучшить качество извлечения данных из текста.