Вопрос или проблема
Всем привет. Я пытался найти способ использовать SHAP для объяснения своих ML моделей. Однако интерпретация графиков beeswarm/summary вызывает у меня некоторую трудность и неоднозначность. Интерпретация зависит от концентрации, дисперсии и частоты больших или малых значений для вывода положительного или отрицательного влияния признака. Мой прямой вопрос:
Существует ли способ собрать эту информацию другим подходом?
Например, вот график beeswarm/summary для набора данных Titanic:
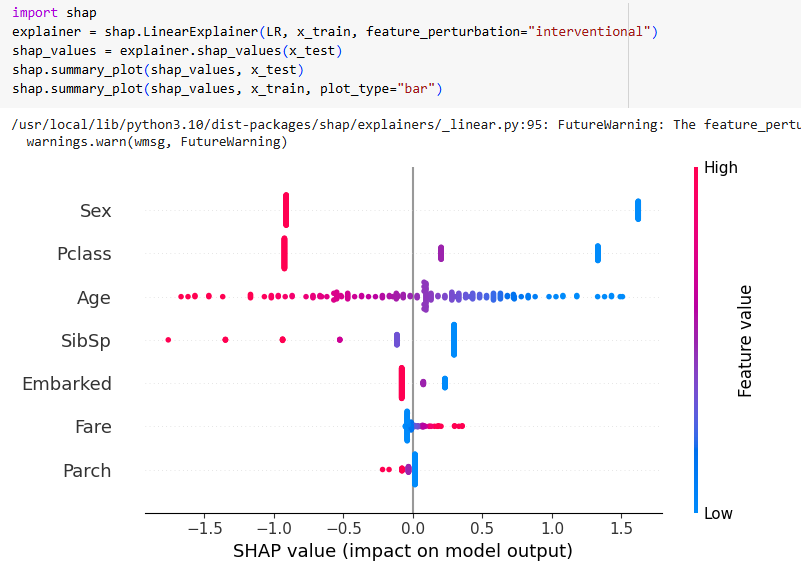
Как видно, более крупные значения признака “пол” (1, представляющий мужчин) приводят к меньшим шансам на выживание, и аналогично, с “возрастом”, чем моложе человек, тем лучше его шансы на выживание. Однако я не мог бы получить эту информацию без обращения к этому конкретному графику, и даже тогда она может быть несколько неоднозначной, так как идет интерпретация на основе изображения.
Поэтому я решил вычислить абсолютные значения SHAP и получил следующее:
Признак Среднее_Абсолютное_Значение_SHAP
1 Пол 1.176998
0 Класс 0.875388
2 Возраст 0.509288
3 SibSp 0.311947
6 Эмбаркация 0.113004
5 Тариф 0.047917
4 Parch 0.023691
Я также собрал средние значения SHAP (не абсолютные) и получил следующее:
Признак Среднее_Значение_SHAP
3 SibSp 0.091608
2 Возраст 0.041808
1 Пол 0.036215
4 Parch -0.001433
5 Тариф -0.001719
6 Эмбаркация -0.001808
0 Класс -0.105661
Обратите внимание, как среднее значение показывает, что “пол” является самым важным признаком. Однако, когда мы смотрим на средние значения SHAP (без абсолютной меры), среднее значение для “пола” очень маленькое. Я подумал, что этот подход возможно направит меня в правильном направлении, но не удалось. Какова будет интерпретация этого? Почему “пол” является самым важным признаком, но его среднее значение SHAP (без абсолютной меры) так мало?
Я был бы очень признателен, если бы вы могли помочь мне с более численным подходом, чтобы описать положительное или отрицательное влияние значений моих признаков на мой результат. В частности, я хочу понять, как разные значения признаков влияют на мою модель—например, чем больше квадратных метров, тем ниже вероятность получения аренды и т.д.
Большое спасибо!
Ответ или решение
В качестве эксперта в области информационных технологий, я понимаю, что интерпретация графиков SHAP, таких как beeswarm и summary plots, может быть труднейшей задачей при анализе моделей машинного обучения. Ваша обеспокоенность по поводу неоднозначности данных графиков вполне обоснована. Давайте рассмотрим альтернативные способы получения инсайтов из SHAP значений и уточним некоторые аспекты ваших расчетов.
Альтернативные подходы к интерпретации SHAP значений
-
Средние абсолютные значения SHAP (Mean Absolute SHAP Values):
Этот подход позволяет нам оценить важность признаков в модели, игнорируя знак. Значение «Sex» действительно имеет самое высокое значение абсолютных SHAP, что говорит о том, что этот признак оказывает наибольшее воздействие на предсказания вашей модели. Вы можете использовать это значение как базовый индикатор, чтобы идентифицировать основные факторы, влияющие на результат. -
Обоснование разности средних SHAP значений (Mean SHAP Values):
Значения, которые вы получили из расчета среднего SHAP, могут вызвать вопросы. Одной из причин, по которой «Sex» имеет высокое среднее абсолютное значение, но низкое среднее SHAP значение, является то, что класс признака «Sex» может быть сильно разбросан по предсказаниям модели (например, доказав, что мужчины имеют более высокий риск), но это не всегда означает, что каждое изменение этого признака влияет на итоговое предсказание одинаково. -
Качественная интерпретация через Q-Q графики (Quantile-Quantile Plot):
Создание Q-Q графиков для ваших SHAP значений может помочь визуализировать распределение и выявить, как исходная переменная (например, пол) влияет на вероятность выживания в зависимости от других факторов. Это даст возможность более детально исследовать состояние и влияние различных категорий. -
Построение частотных графиков (Frequency Plots):
Частотные графики могут помочь вам визуализировать, как разные значения признака (например, возраст) распределяются среди предсказаний. Это позволит вам, не отвлекаясь на рамках существующих графиков, видеть конкретные интервалы, которые оказывают наибольшее влияние на результат. -
Параллельные координаты (Parallel Coordinates Plot):
Этот график может быть использован для отображения взаимодействия между несколькими переменными. Например, вы можете одновременно увидеть, как «Sex», «Age» и «Pclass» влияют на вероятность выживания. Это даст возможность понимать, как разные факторы могут сосуществовать и взаимодействовать.
Ваша задача более количественно описать, как различные характеристики влияют на предсказания модели. Можно использовать следующие методики:
- Оценка эффекта признаков с помощью частичных зависимостей (Partial Dependence Plots): Эти графики показывают, как изменение одного или двух признаков влияет на предсказание, что позволяет вам получить больше информации о таких нерегулярных данных.
- Группировка данных (Group-based Analysis): Рассмотрите возможность разбить ваши данные на группы и оценить влияние различных переменных по этим группам.
Заключение
Таким образом, хотя графики SHAP, такие как beeswarm, предоставляют полезные визуализации, различные количественные и качественные методы могут обеспечить более глубокое понимание механики модели. Используйте комбинацию средних SHAP значений, сопоставительных графиков и методов визуализации для формирования более полного и точного представления о вашем анализе. Вопрос о том, как точно интерпретировать результаты, требует внимательного подхода, но совмещение данных методов несомненно обогатит ваше понимание ваших данных и модели.