Вопрос или проблема
У меня есть pdf файл (ссылка ниже).
Мне нужно извлечь из него ключевые слова, а также узнать их частоту в pdf файле. Например, 'Java':42, 'наследование':3.
Мне нужно сохранить ключевые слова с их весами в excel таблице.
Не могли бы вы подсказать, как это сделать на python.
https://drive.google.com/file/d/1gZCnlhwVMBIE0SugUUxDIgQrfVz-cDQR/view
Это интересный вопрос! Давайте конвертируем все ваши PDF файлы в текстовые документы, чтобы вы могли пройтись по каждому из них, прочитать все содержимое и затем отчитаться об этом в MS Excel.
Sub OpenAndReadWordDoc()
Rows("2:1000000").Select
Range(Selection, Selection.End(xlDown)).Select
Selection.ClearContents
Range("A1").Select
' предполагается, что предыдущая процедура была выполнена
Dim oWordApp As Word.Application
Dim oWordDoc As Word.Document
Dim blnStart As Boolean
Dim r As Long
Dim sFolder As String
Dim strFilePattern As String
Dim strFileName As String
Dim sFileName As String
Dim ws As Worksheet
Dim c As Long
Dim n As Long
Dim iCount As Long
Dim strSearch As String
'~~> Создайте объект приложения Word
On Error Resume Next
Set oWordApp = GetObject(, "Word.Application")
If Err Then
Set oWordApp = CreateObject("Word.Application")
' Мы начали Word для этого макроса
blnStart = True
End If
On Error GoTo ErrHandler
Set ws = ActiveSheet
r = 1 ' начальная строка для скопированного текста из документа Word
' Последний столбец
n = ws.Range("A1").End(xlToRight).Column
sFolder = "C:\Users\Excel\Desktop\test\"
'~~> Это расширение, с которым вы хотите работать
strFilePattern = "*.doc*"
'~~> Проходите по папке, чтобы получить файлы word
strFileName = Dir(sFolder & strFilePattern)
Do Until strFileName = ""
sFileName = sFolder & strFileName
'~~> Откройте документ word
Set oWordDoc = oWordApp.Documents.Open(sFileName)
' Увеличьте номер строки
r = r + 1
' Введите имя файла в столбец A
ws.Cells(r, 1).Value = sFileName
ActiveCell.Offset(1, 0).Select
ActiveSheet.Hyperlinks.Add Anchor:=Sheets("Sheet1").Range("A" & r), Address:=sFileName, _
SubAddress:="A" & r, TextToDisplay:=sFileName
' Перебирайте столбцы
For c = 2 To n
If oWordDoc.Content.Find.Execute(FindText:=Trim(ws.Cells(1, c).Value), _
MatchWholeWord:=True, MatchCase:=False) Then
strSearch = ws.Cells(1, c).Value
iCount = 0
With ActiveDocument.Content.Find
.Text = strSearch
.Format = False
.Wrap = wdFindStop
Do While .Execute
iCount = iCount + 1
Loop
End With
ws.Cells(r, c).Value = iCount
End If
Next c
oWordDoc.Close SaveChanges:=False
'~~> Найдите следующий файл
strFileName = Dir
Loop
ExitHandler:
On Error Resume Next
' закройте приложение Word
Set oWordDoc = Nothing
If blnStart Then
' Мы начали Word, так что мы закрываем его
oWordApp.Quit
End If
Set oWordApp = Nothing
Exit Sub
ErrHandler:
MsgBox Err.Description, vbExclamation
Resume ExitHandler
End Sub
Function GetDirectory(path)
GetDirectory = Left(path, InStrRev(path, "\"))
End Function
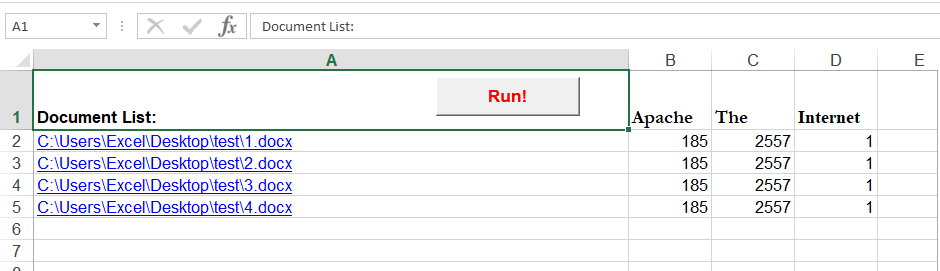
Проверьте приведенный выше код и дайте обратную связь. Моя настройка выглядит, как на изображении ниже.
Ответ или решение
Для извлечения ключевых слов из PDF-файла с помощью Python можно использовать несколько библиотек: PyPDF2 для чтения PDF-документов, collections для подсчета частоты ключевых слов и pandas для сохранения данных в Excel. Давайте рассмотрим шаг за шагом, как можно это реализовать.
Шаг 1: Установка необходимых библиотек
Убедитесь, что у вас установлены необходимые библиотеки. Вы можете установить их с помощью pip:
pip install PyPDF2 pandas openpyxlШаг 2: Извлечение текста из PDF
Начнем с написания кода, который будет открывать PDF-файл и извлекать текст из него. Ниже приведен пример кода:
import PyPDF2
from collections import Counter
import pandas as pd
# Функция для извлечения текста из PDF
def extract_text_from_pdf(pdf_path):
text = ""
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text += page.extract_text()
return textШаг 3: Извлечение ключевых слов и подсчет их частоты
Теперь мы добавим функциональность для извлечения ключевых слов и их частоты. Мы будем использовать Counter из модуля collections для подсчета количества вхождений.
def extract_keywords(text):
# Приводим текст к нижнему регистру и разбиваем его на слова
words = text.lower().split()
# Используем Counter для подсчета слова
word_counts = Counter(words)
# Сортируем по частоте
sorted_word_counts = dict(sorted(word_counts.items(), key=lambda item: item[1], reverse=True))
return sorted_word_countsШаг 4: Запись данных в Excel
Теперь мы можем записать полученные ключевые слова и их частоту в Excel-файл с помощью Pandas.
def save_to_excel(keyword_counts, output_file):
df = pd.DataFrame(keyword_counts.items(), columns=['Keyword', 'Frequency'])
df.to_excel(output_file, index=False)Главная функция
Объединим все части в одну главную функцию:
def main(pdf_path, output_file):
# Извлечение текста из PDF
text = extract_text_from_pdf(pdf_path)
# Извлечение ключевых слов и их частоты
keyword_counts = extract_keywords(text)
# Сохранение в Excel
save_to_excel(keyword_counts, output_file)
print(f'Ключевые слова успешно сохранены в {output_file}')
if __name__ == "__main__":
PDF_FILE_PATH = 'path/to/your/file.pdf' # Укажите путь к вашему PDF файлу
OUTPUT_FILE_PATH = 'keyword_frequencies.xlsx' # Укажите имя выходного файла
main(PDF_FILE_PATH, OUTPUT_FILE_PATH)Заключение
Данный код будет извлекать текст из указанного PDF-файла, вычислять частоту вхождений ключевых слов и сохранять результаты в Excel. Убедитесь, что файл PDF доступен и правильно указан в коде. Этот подход может быть адаптирован для учета дополнительных требований или специфики вашего проекта.
Пожалуйста, протестируйте этот код на вашем PDF-документе и сделайте необходимые корректировки, если потребуется.