Вопрос или проблема
В настоящее время я пытаюсь создать автоэнкодер, который сжимает 3D-объем, где каждое значение представляет собой плотность данного объема. Архитектура – это UNet без пропускных соединений. Оптимизатор – AdamW с коэффициентом обучения 0.0002 и beta1 равным 0.5. Я использую три функции потерь: MSE между входом и восстановленным, 3D-норму Фробениуса восстановленной плотности и функцию потерь сегментации, где я хочу, чтобы области с ненулевой плотностью совпадали.
Моя проблема в том, что автоэнкодер, пох кажется, не сходитс. После нескольких эпох он выдает результаты, которые ближе к начальному входу, но если я обучаю его слишком долго, функция потерь резко увеличивается, и результат совершенно не похож на вход.
С вашего опыта, что может вызывать это? Какие инструменты/советы я могу использовать, чтобы уменьшить не-сходимость? Какие вопросы я должен задавать себе?
Вот график ошибки MSE для моего валидационного набора.
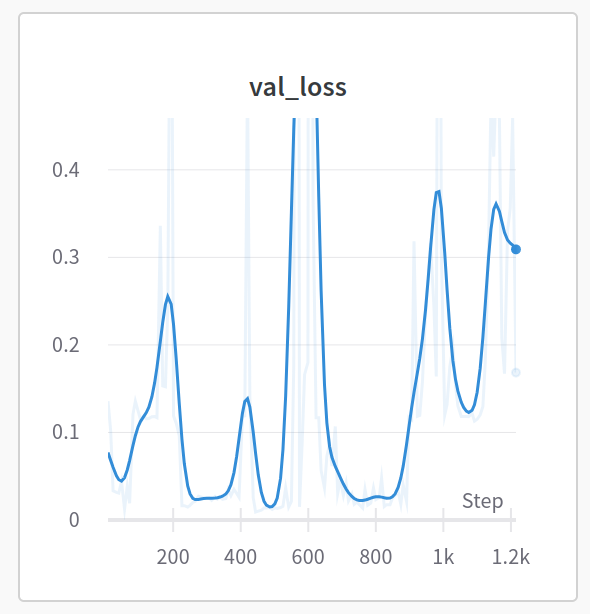
Перед сжатием 3D-объемов я рекомендую сначала сжать 2D-поверхности, так как это проще для выявления причин расхождений, и это также легко масштабировать до 3D.
Затем вы можете попробовать SGD или RMSProp вместо AdamW. Даже если Adam – это отличный алгоритм, он менее устойчив, чем SGD: Adam использует другое правило обновления, которое включает скользящие средние градиентов модели и вторых моментов. Это может привести к большему колебанию Adam, особенно когда данные шумные или ландшафт оптимизации сильно не выпуклый. В отличие от этого, SGD использует только градиент функции потерь, что может сделать его более стабильным и легким для настройки.
Наконец, вы можете использовать Velo, который является обученным оптимизатором. Он должен справиться со сложными проблемами сходимости, как у вас.
https://github.com/google/learned_optimization/tree/main/learned_optimization/research/general_lopt
Ответ или решение
Советы по обеспечению сходимости автоэнкодера
Автоэнкодеры являются мощными инструментами для сжатия и анализа данных, однако их сходимость может быть сложной задачей, особенно в таких сложных задачах, как сжатие 3D-объемов. Ниже представлены основные причины, по которым ваш автоэнкодер может не сойтись, а также рекомендации для решения таких проблем.
1. Понимание архитектуры и функции потерь
Ваш автоэнкодер основан на архитектуре UNet без соединений, что уже является необычным подходом, поскольку сетевые соединения часто помогают в восстановлении деталей. Кроме того, использование трех различных функций потерь может вызвать сложности в сходимости, так как разные функции могут конфликтовать друг с другом.
Рекомендации:
- Упрощение функции потерь: Попробуйте поэкспериментировать с одной или двумя функциями потерь перед добавлением третьей. Это поможет вам лучше понять, какая из потерь наилучшим образом помогает сети.
- Рассмотрите возможность использования сегментационной потери только на финальном выходе, чтобы снизить влияние на скрытые слои.
2. Настройки оптимизатора
Вы используете AdamW с потенциально хорошими настройками, однако он может быть менее стабильным по сравнению с классическими методами, такими как SGD и RMSProp, особенно в условиях большого шума.
Рекомендации:
- Попробуйте использовать SGD или RMSProp для лучшей стабильности, особенно если ваш набор данных шумный.
- Если вы хотите продолжить использовать AdamW, попробуйте изменить параметр learning rate, особенно если наблюдаете резкие колебания в потере. Иногда уменьшение learning rate может улучшить результаты.
3. Переобучение
Если вы замечаете, что ваш автоэнкодер демонстрирует улучшение, а затем его производительность резко падает, это может указывать на переобучение.
Рекомендации:
- Используйте раннюю остановку (Early Stopping) для предотвращения переобучения. Это позволяет остановить обучение, когда производительность на валидационном наборе перестает улучшаться.
- Примените регуляризацию к вашим функциям потерь, чтобы предотвратить переобучение. Например, можно использовать L2-регуляризацию.
4. Рекомендуемые этапы заранее
Перед сжатием 3D-объемов, действительно, рекомендуется проверить вашу архитектуру на двухмерных данных. Это значительно упростит отладку, и вы сможете непосредственно увидеть, как ваши изменения влияют на сходимость.
5. Приборы для диагностики
Чтобы лучше понять, что происходит во время обучения и как изменяется ваш автоэнкодер:
- Визуализируйте внутреннее представление модели чтобы понять, какие паттерны она улавливает.
- Проверяйте не только глобальную потерю, но и поэтапные потери для всего множества.
6. Сообщество и ресурсы
Изучение информации из сообществ, таких как GitHub или специализированные форумы по машинному обучению, может помочь вам найти аналогичные проблемы и решения. Использование таких инструментов, как Velo, может оказаться полезным, так как это обучаемый оптимизатор, который может помочь вам достичь лучшей сходимости.
Заключение
В зависимости от сложности ваших данных и особенностей архитектуры, проблема сходимости может быть решена с помощью экспериментов с архитектурой, функцией потерь и оптимизатором. Уменьшение сложности вашей задачи снижает вероятность возникновения проблем со сходимостью. Постоянно отслеживайте результаты вашей работы, адаптируйте решения и не бойтесь экспериментировать.