Вопрос или проблема
Я пытаюсь использовать модель Seq2Seq для прогнозирования данных производства на фабрике, используя модель Encoder-Decoder с добавлением механизма внимания. Я немного застрял, так как выход модели, похоже, является константой и имеет такую же длину последовательности, что и вход, тогда как на самом деле я хотел бы иметь возможность указать, что, скажем, хочу прогнозировать на 3 (или любое другое количество) месяцев вперед.
Вот 2 диаграммы архитектуры Seq2Seq и механизма внимания, которые я хочу построить:


Цель
Насколько я понимаю, я хочу прогнозировать объем производства определенного материала с этой фабрики на будущее. Таким образом, его размерность равна $1$ и это, конечно, целое число.
Энкодер
Энкодер принимает на вход последовательность длиной $168$, где каждый вход представляет собой данные за $20$ предыдущих дней, а также $37$ фабричных характеристик, таких как количество работников и т.д.
Декодер
Здесь я запутался и сталкиваюсь с проблемами в своем коде. Опять же, насколько я понимаю, декодер должен принимать на вход уровни производства за предыдущие временные шаги (что означает размерность $1$), а также предыдущие скрытое состояние и ячейку.
Код
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, p):
super(EncoderRNN, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size,
num_layers, dropout = p,
bidirectional = True)
self.fc_hidden = nn.Linear(hidden_size*2, hidden_size)
self.fc_cell = nn.Linear(hidden_size*2, hidden_size)
def forward(self, input):
print(f"Форма входа энкодера: {input.shape}")
encoder_states, (hidden, cell_state) = self.lstm(input)
print(f"Скрытое состояние энкодера: {hidden.shape}")
print(f"Состояние ячейки энкодера: {cell_state.shape}")
hidden = self.fc_hidden(torch.cat((hidden[0:1], hidden[1:2]), dim = 2))
cell = self.fc_cell(torch.cat((cell_state[0:1], cell_state[1:2]), dim = 2))
print(f"Скрытое состояние энкодера: {hidden.shape}")
print(f"Состояние ячейки энкодера: {cell.shape}")
return encoder_states, hidden, cell
class Decoder_LSTMwAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, p):
super(Decoder_LSTMwAttention, self).__init__()
self.rnn = nn.LSTM(hidden_size*2 + input_size, hidden_size,
num_layers)
self.energy = nn.Linear(hidden_size * 3, 1)
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.Softmax(dim=0)
self.dropout = nn.Dropout(p)
self.relu = nn.ReLU()
self.attention_combine = nn.Linear(hidden_size, hidden_size)
def forward(self, input, encoder_states, hidden, cell):
input = input.unsqueeze(0)
input = input.unsqueeze(0)
input = self.dropout(input)
sequence_length = encoder_states.shape[0]
h_reshaped = hidden.repeat(sequence_length, 1, 1)
concatenated = torch.cat((h_reshaped, encoder_states), dim = 2)
print(f"Размер сопряженного: {concatenated.shape}")
energy = self.relu(self.energy(concatenated))
attention = self.softmax(energy)
attention = attention.permute(1, 0, 2)
encoder_states = encoder_states.permute(1, 0, 2)
context_vector = torch.einsum("snk,snl->knl", attention, encoder_states)
rnn_input = torch.cat((context_vector, input), dim = 2)
output, (hidden, cell) = self.rnn(rnn_input, hidden, cell)
output = self.fc(output).squeeze(0)
return output, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, source, target, teacher_force_ratio=0.5):
batch_size = source.shape[1]
target_len = target.shape[0]
outputs = torch.zeros(target_len, batch_size).to(device)
encoder_states, hidden, cell = self.encoder(source)
x = target[0]
for t in range(1, target_len):
output, hidden, cell = self.decoder(x, encoder_states, hidden, cell)
outputs[t] = output
best_guess = output.argmax(1)
x = target[t] if random.random() < teacher_force_ratio else best_guess
return outputs
Режим обучения
def Seq2seq_trainer(model, optimizer, train_input, train_target,
test_input, test_target, criterion, num_epochs):
train_losses = np.zeros(num_epochs)
validation_losses = np.zeros(num_epochs)
for it in range(num_epochs):
optimizer.zero_grad()
outputs = model(train_input, train_target)
loss = criterion(outputs, train_target)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
optimizer.step()
train_losses[it] = loss.item()
test_outputs = model(test_input, test_target)
validation_loss = loss_function(test_outputs, test_target)
validation_losses[it] = validation_loss.item()
if (it + 1) % 25 == 0:
print(f'Эпоха {it+1}/{num_epochs}, Обучающая потеря: {loss.item():.4f}, Потеря валидации: {validation_loss.item():.4f}')
return train_losses, validation_losses
Результаты, которые я получаю
Проблема, похоже, в том, что декодер предсказывает одно и то же значение каждый раз и не улавливает шум в данных.

Разбирая ряд вопросов, во-первых
Я хочу прогнозировать на 3 месяца вперед.
Вам нужно данные за как минимум 3+ месяца, чтобы выполнить эту задачу. Это означает, что ваш "горизонт прогнозирования" должен быть подмножеством вашего набора данных, в котором вы можете определить, насколько далеко вперед вы хотите делать прогнозы. Например, см. изображение ниже:

Декодер должен принимать уровни производства за предыдущие временные шаги на вход (что означает размерность 1), а также предыдущее скрытое состояние и состояние ячейки.
Я думаю, что вы смешиваете архитектуру пуллинга внимания с концепциями самовнимания/архитектуры трансформеров.
- В типичном RNN с энкодером/декодером декодер должен принимать скрытое состояние, выходящее из каждой LSTM-ячейки/временного шага. Если вы не пытаетесь использовать более экспериментальный выход, состояние ячейки, а также входные данные не должны передаваться декодеру. Если вы используете внимание Лунга/аддитивный пуллинг внимания, то снова только скрытое состояние необходимо для его вычисления. Я не уверен, что ваш метод внимания полностью правильный. Я вставляю ниже пример того, как ваш декодер с аддитивным вниманием должен выглядеть:
class AttnDecoderRNN(nn.Module):
"""
Courtesy of https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
"""
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
- Правильно, вы утверждаете, что входные данные и скрытое состояние должны передаваться декодеру, и я полагаю, вы имеете в виду архитектуру самовнимания. Для этой модели нет единиц декодера/декодера, но каждый вход абстрагируется в латентные пространства запроса, ключа и значения, как на следующей диаграмме:
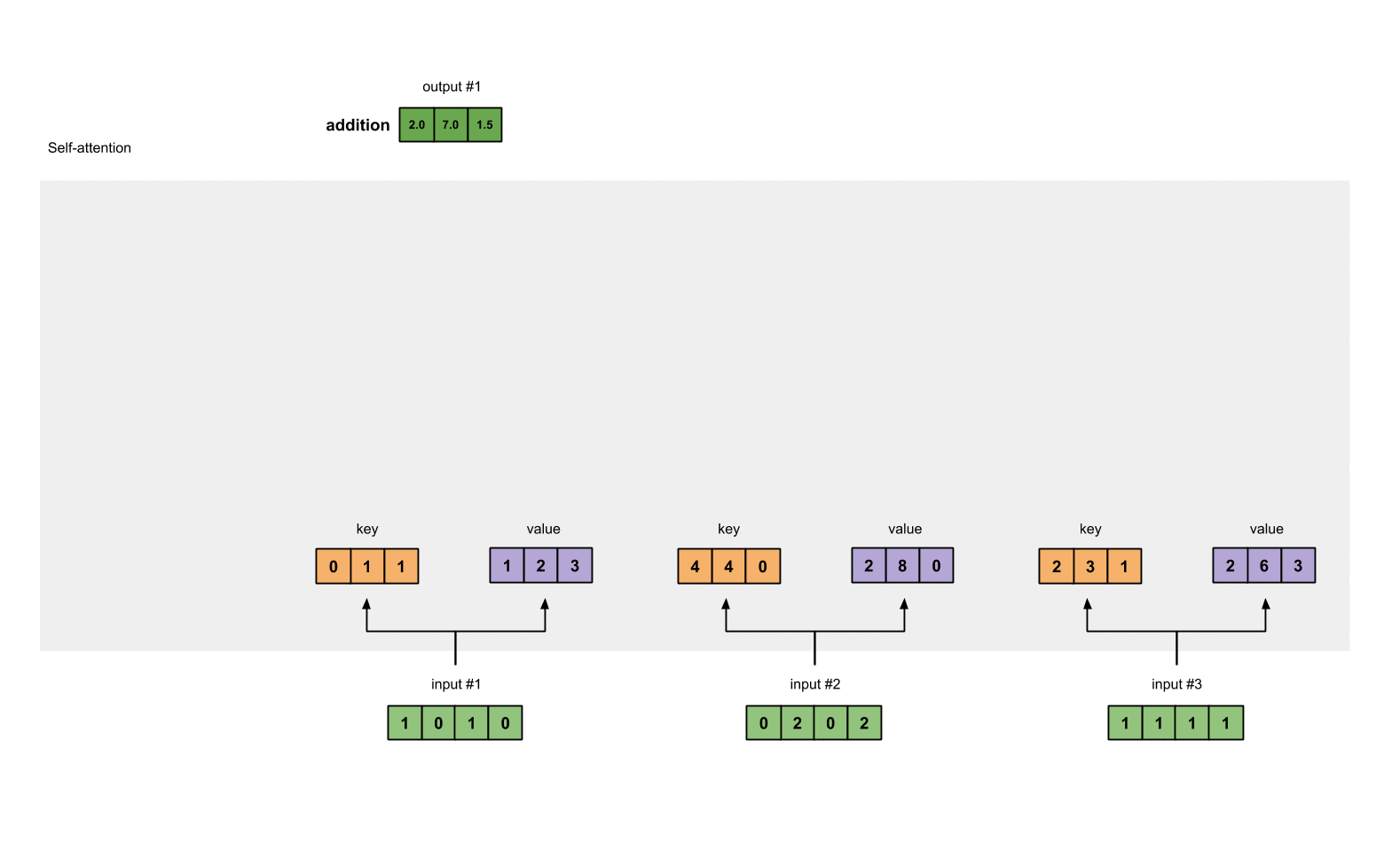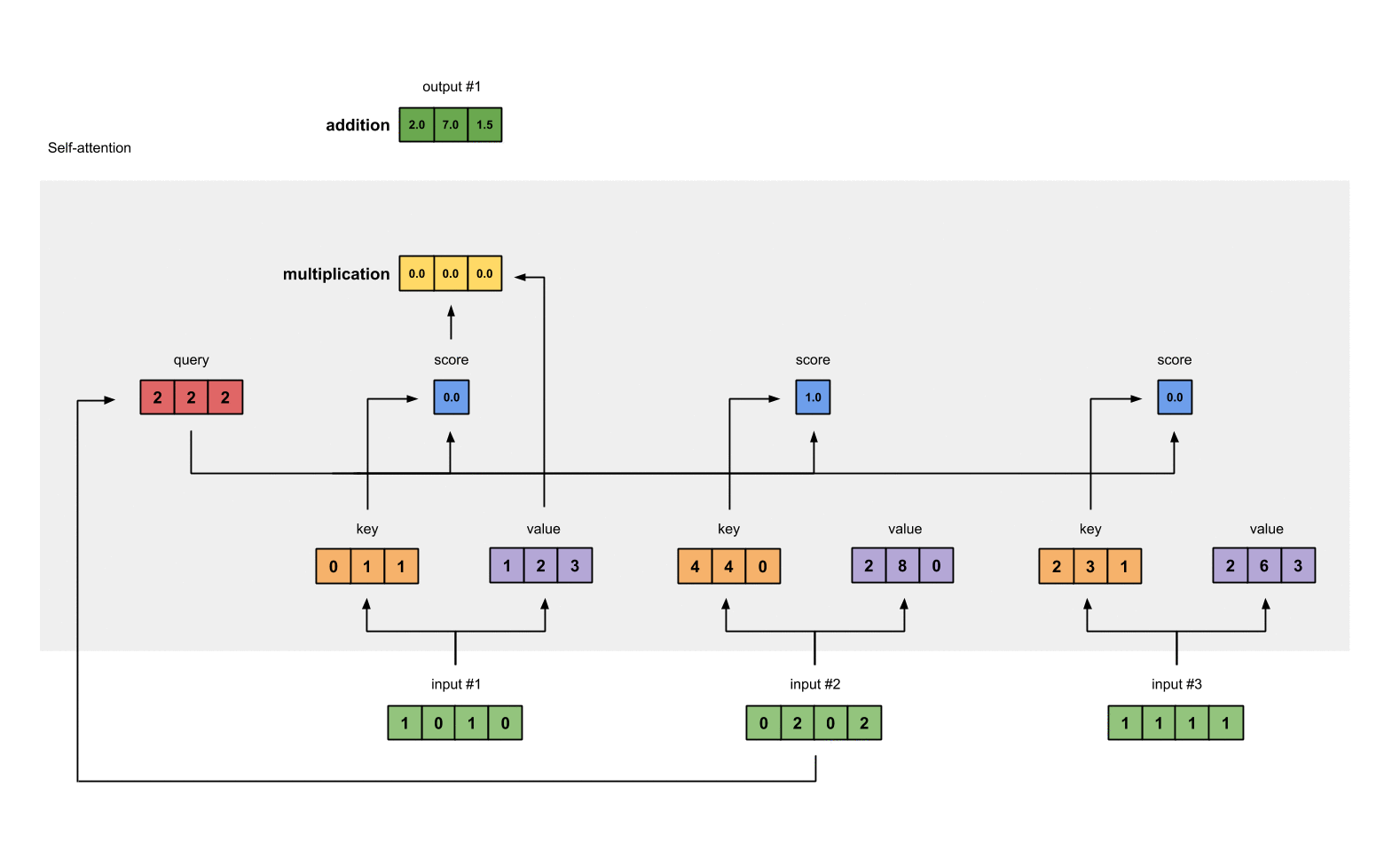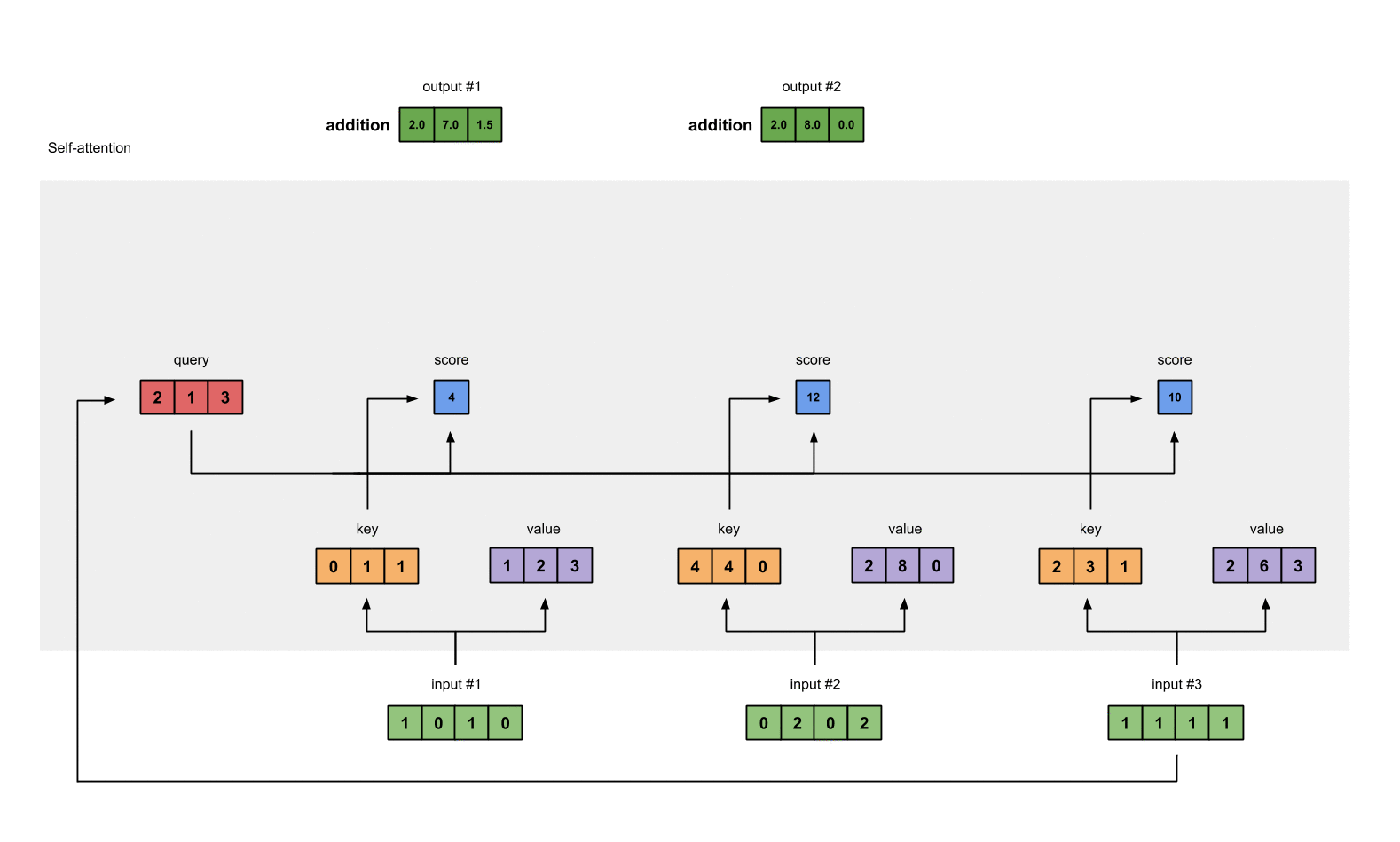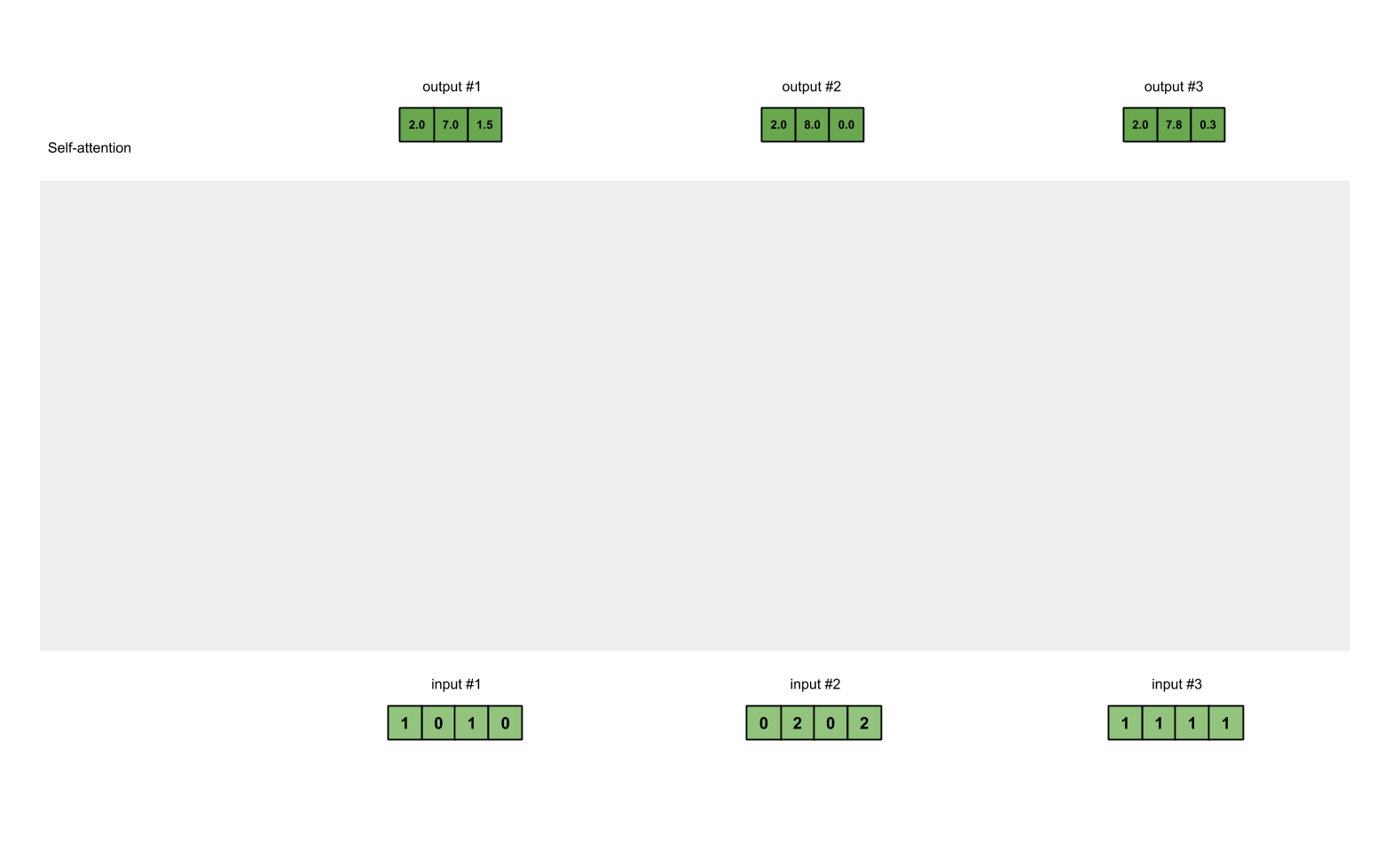
Вы можете прочитать больше об архитектуре самовнимания здесь https://towardsdatascience.com/self-attention-5b95ea164f61, прежде чем решите, как хотите продолжать решать вашу проблему.
Ответ или решение
Прогнозирование данных о производстве на заводе с помощью модели Seq2Seq Encoder-Decoder с механизмом внимания
Вы столкнулись с задачей многослойного прогнозирования данных о производстве на заводе, используя архитектуру Seq2Seq с механизмом внимания. Ваша цель — предсказать объем производства в течение следующего времени, например, на три месяца вперед. При этом важно правильно настроить модель, чтобы избежать постоянных значений в выходных данных, которые не отражают реальную динамику.
Основные элементы модели
-
Цель прогноза: Необходимо предсказать объем производства, который является одномерным значением (целым числом).
-
Энкодер: На вход энкодера подается последовательность длиной 168, включающая данные за последние 20 дней и 37 параметров, касающихся производственного процесса (например, количество работников).
-
Декодер: Здесь происходят основные сложности. Декодер должен принимать предыдущие уровни производства как входные данные, а также скрытые и ячеистые состояния из энкодера.
Предложенные изменения
-
Структура декодера: Для того чтобы декодер мог предсказывать значения на несколько шагов вперед, необходимо модифицировать его так, чтобы он генерировал последовательность выходов длиной, соответствующей вашему "горизонту прогноза". Это означает, что декодер должен уметь обрабатывать последовательное предсказание в цикле, подавая предыдущее предсказание обратно в модель.
-
Замены в строках кода:
- В вашем текущем подходе вы используете "teacher forcing", что хорошо, но необходимо убедиться, что декодер получает на вход именно те значения, которые он должен предсказывать.
- Вы должны структурировать декодер так, чтобы он генерировал последовательность выходных значений (например, три шага), а не одномерный список, который повторяется для каждого временного шага.
-
Обновление функции
forward: Чтобы декодер предсказывал значения на три месяца вперед, можно изменить цикл в методеforwardклассаSeq2Seq, чтобы он генерировал прогноз на несколько временных шагов:
def forward(self, source, target, teacher_force_ratio=0.5):
batch_size = source.shape[1]
target_len = <number_of_months> # Укажите количество шагов, на которые хотите прогнозировать
outputs = torch.zeros(target_len, batch_size, self.decoder.output_size).to(device)
encoder_states, hidden, cell = self.encoder(source)
# Начальное значение для декодера (например, токен начала последовательности)
x = target[0]
for t in range(target_len):
output, hidden, cell = self.decoder(x, encoder_states, hidden, cell)
# Сохраняем предсказание для текущего времени
outputs[t] = output
# Получаем лучшее предсказание
best_guess = output.argmax(1)
# Используем teacher forcing с вероятностью teacher_force_ratio
x = target[t] if random.random() < teacher_force_ratio else best_guess
return outputsПроблемы с предсказанием постоянного значения
Проблема с предсказанием постоянного значения может быть вызвана несколькими факторами:
-
Проблемы с данными: Проверьте масштабирование и нормализацию входных данных. Перепроверьте, что данные поступают правильно и не содержат аномалий.
-
Переобучение или недообучение: Если ваша модель слишком сложная или слишком простая, она может не распознавать зависимости. Это может быть решено регулированием гиперпараметров или изменением архитектуры модели.
-
Коэффициенты потерь: Следите за значениями функции потерь при обучении. Если значения остаются слишком высокими или не меняются, это может указывать на проблемы в настройках модели или данных.
Заключение
Расширив знания о механизме внимания и правильно настроив декодер для многослойного прогноза, вы сможете добиться более точных и разнообразных предсказаний. Следуя вышеизложенным рекомендациям, вы сможете улучшить работу вашего Seq2Seq моделирования и получить более надежные результаты в прогнозах объемов производства на заводе.