У меня есть случай, когда у меня есть таблица “tab”, которая хранит данные (с ключами по символу и времени), а также вторая таблица “summ”, которая хранит экспоненциальное сглаженное скользящее среднее данных из первой таблицы. Я настроил так, что когда в первую таблицу добавляются данные, это запускает расчет скользящего среднего для соответствующих строк во второй таблице.
Однако я не могу понять, как хорошо восстановить состояние для продолжения расчетов скользящего среднего. Вместо этого каждый раз при вызове триггера расчет начинается заново. Как мне сохранить состояние агрегации в конце?
У меня есть минимальный пример по адресу https://dbfiddle.uk/6dqXCwIQ, который также воспроизведен ниже.
Сначала создается таблица, которая будет содержать несглаженные данные, а также сводная таблица, которая будет хранить сглаженные данные. Также есть триггер для заполнения второй таблицы на основе первой.
/* Создание таблицы, которая будет содержать несглаженные данные */
create table tab (
symbol text,
time_to timestamptz,
something int4,
PRIMARY KEY(time_to, symbol)
);
CREATE UNIQUE INDEX index_name2 ON tab USING btree (symbol, time_to);
/* Создание сводной таблицы и триггера, который будет заполнять ее при добавлении данных в tab. */
CREATE OR REPLACE FUNCTION smoother_state(state double precision[],
newval double precision, frac double precision)
RETURNS double precision[]
LANGUAGE plpgsql
IMMUTABLE PARALLEL SAFE LEAKPROOF
AS $function$
declare
resul double precision := case when state[1] is null then newval else state[1] * (1-frac) + newval * frac end;
begin
return ARRAY[resul, coalesce(state[2] + 1, 1)];
END;
$function$
;
CREATE OR REPLACE AGGREGATE smoother(val double precision, frac double precision) (
SFUNC = smoother_state,
STYPE = double precision[2]
);
create table summ (
symbol text,
time_to timestamptz,
smoothed_something double precision,
number_of_periods double precision,
PRIMARY KEY(time_to, symbol)
);
CREATE UNIQUE INDEX index_name3 ON summ USING btree (symbol, time_to);
/* Создание триггера.
Я полагаю, что он должен считывать значения smoothed_something и number_of_periods для символа
и использовать их в качестве начального вектора состояния.
*/
CREATE OR REPLACE FUNCTION do_update()
RETURNS trigger
LANGUAGE plpgsql
PARALLEL SAFE STRICT LEAKPROOF
AS $function$
DECLARE
BEGIN
with a as (select symbol, time_to, something,
smoother(something, 0.3) over (partition by symbol order by time_to) as smoo
FROM newtab
), b as (select symbol, time_to, smoo[1] as smoothed_something, smoo[2] as number_of_periods from a)
INSERT INTO summ (symbol, time_to, smoothed_something, number_of_periods) select * from b;
RETURN null;
END;
$function$
;
create trigger update_smoothed after
insert on tab
referencing new table as newtab
for each statement
execute function do_update()
Первый раз добавляя данные, обе таблицы tab и summ выглядят корректно.
insert into tab (symbol, time_to, something) values
('a', '2022-01-01 00:00:15+01:00'::timestamptz, 15),
('b', '2021-01-01 00:00:15+01:00'::timestamptz, 18),
('b', '2022-01-01 00:00:15+01:00'::timestamptz, 13),
('b', '2023-01-01 00:00:15+01:00'::timestamptz, 11),
('b', '2024-01-01 00:00:15+01:00'::timestamptz, 3),
('c', '2022-01-01 00:00:16+01:00'::timestamptz, 15),
('c', '2022-01-01 00:00:17+01:00'::timestamptz, 150);
Во второй раз, вставляя данные, таблица tab выглядит корректно, но summ не такова, так как агрегация начинается с нулевого состояния.
insert into tab (symbol, time_to, something) values
('a', '2022-06-01 00:00:15+01:00'::timestamptz, 150),
('a', '2022-07-01 01:00:15+01:00'::timestamptz, 170),
('b', '2024-08-01 00:00:15+01:00'::timestamptz, 180),
('b', '2024-09-01 00:00:15+01:00'::timestamptz, 130);
Вы можете увидеть результирующие данные в каждой таблице ниже, а также на сайте fiddle.
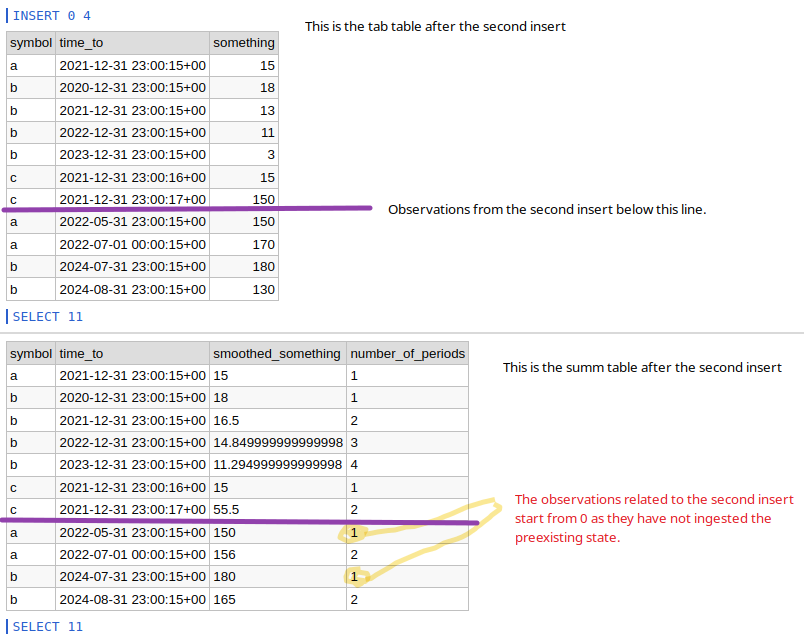
По этой проблеме:
- Существует ли способ модифицировать триггер, чтобы он вводил правильное состояние при повторной агрегации? Я с радостью приму условие, что мы всегда добавляем только данные, которые происходят позже по времени, чем более ранние наблюдения.
- Существует ли лучший способ добиться этого? У меня много данных, и я хочу избежать создания материализованного представления (так как это занимает слишком много времени для обновления всего).
Ответ
Для решения проблемы с агрегацией и сохранением состояния в функции агрегирования Postgres мы можем изменить триггер, чтобы он использовал значения последнего сглаженного результата из таблицы summ как начальное состояние для дальнейших вычислений. Ниже приведен полное решение.
Шаги решения:
-
Изменение функции триггера — мы будем извлекать последнее сглаженное значение из таблицы
summдля символа, прежде чем выполнять обновление. - Корректировка функции агрегирования — чтобы использовать извлеченные значения в качестве начального состояния.
Измененный код:
-- Функция для обновления триггера
CREATE OR REPLACE FUNCTION do_update()
RETURNS trigger
LANGUAGE plpgsql
PARALLEL SAFE STRICT LEAKPROOF
AS $function$
DECLARE
last_state double precision[];
BEGIN
-- Получаем последнее сглаженное значение для соответствующего символа
SELECT ARRAY[smoothed_something, number_of_periods] INTO last_state
FROM summ
WHERE symbol = NEW.symbol
ORDER BY time_to DESC
LIMIT 1;
-- Выполняем агрегацию с использованием последних значений состояния
WITH a AS (
SELECT symbol, time_to, something,
smoother(something, 0.3)
OVER (PARTITION BY symbol ORDER BY time_to
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS smoo
FROM tab
WHERE symbol = NEW.symbol
AND time_to <= NEW.time_to
),
b AS (
SELECT symbol, time_to,
COALESCE(smoo[1], last_state[1]) AS smoothed_something,
COALESCE(smoo[2] + (last_state[2]::int * 1), 1) AS number_of_periods
FROM a
)
INSERT INTO summ (symbol, time_to, smoothed_something, number_of_periods)
SELECT * FROM b
ON CONFLICT (symbol, time_to)
DO UPDATE SET smoothed_something = EXCLUDED.smoothed_something,
number_of_periods = EXCLUDED.number_of_periods;
RETURN null;
END;
$function$;
-- Триггер, который активируется после вставки в таблицу tab
CREATE TRIGGER update_smoothed
AFTER INSERT ON tab
REFERENCING NEW TABLE AS newtab
FOR EACH STATEMENT
EXECUTE FUNCTION do_update();Объяснение изменений:
-
Получение предыдущего состояния: Мы используем SQL-запрос в функции триггера для получения последнего сглаженного значения и числа периодов для данного символа. Это делается с помощью подзапроса, который выбирает данные из таблицы
summ. -
Использование предыдущего состояния: В блоке
WITHобновляется логика, гдеsmoothed_somethingбудет вычисляться с использованием функцииsmoother, учитывая последнее состояние (если оно существует). - Обновление или вставка: Мы используем
ON CONFLICT, чтобы обновить уже существующие записи в таблицеsumm. Это позволяет поддерживать актуальность данных без дублирования.
Заключение:
С этой реализацией, при каждом добавлении новых значений в таблицу tab, триггер будет корректно сохранять и обновлять состояние сглаживания в таблице summ, что позволяет продолжить вычисление с использованием последних результатов. Это решение эффективно для большого объема данных и исключает необходимость в материальных представлениях.