Я визуализировал отсутствующие данные в своем проекте на Kaggle:
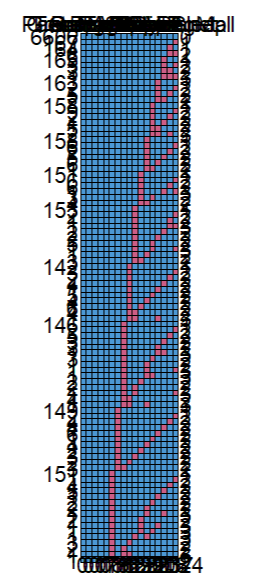
На мой взгляд, это явно показывает, что существует определенный шаблон в недостающих данных (вероятно, созданный человеком, чтобы бросить вызов людям, работающим над проектом).
Однако я просто не знаю, как с этим работать. Я мог бы просто вставить среднее, медиану или моду для каждой переменной, но мне интересно, есть ли лучшие практики в этом случае и дополнительные идеи, которые я не получил из визуализации.
Ответ
Когда вы сталкиваетесь с паттерном пропущенных данных, важно правильно подойти к их обработке, чтобы минимизировать негативное влияние на ваши модели и выводы. Вот несколько рекомендаций и шагов, которые вы можете предпринять:
1. Анализ паттерна отсутствующих данных
Для начала важно понять, почему данные отсутствуют. Если вы заметили, что пропуски имеют определенный паттерн, это может означать, что пропущенные значения не случайны (MNAR – Missing Not At Random). Попробуйте выявить, по каким признакам возникают пропуски. Например, определенные значения в других переменных могут быть связаны с отсутствием данных в интересующей вас переменной.
2. Визуализация данных
Используйте визуализации, такие как карты тепла (heatmaps) и графики зависимостей, чтобы проиллюстрировать зависимости между переменными и понять, к каким данным касается проблема отсутствующих значений. Это поможет вам увидеть возможные связи между пропущенными данными и другими переменными.
3. Импутация данных
В зависимости от характера паттерна пропускам можно применить различные методы импутации:
-
Методы статистической импутации: если пропущенные данные случайные, можно использовать среднее, медиану или моду для замены отсутствующих значений. Однако это может исказить распределение данных.
-
Модели предсказания: если пропуски имеют определенный паттерн, рассмотрите использование алгоритмов машинного обучения (например, регрессии, деревьев решений), чтобы предсказать отсутствующие значения на основе доступной информации.
- Методы, учитывающие взаимосвязи: некоторые методы, такие как метод k ближайших соседей (KNN) или метод множественной иммутации, могут использовать доступные данные для более точной оценки пропущенных значений.
4. Удаление данных
Если часть данных имеет слишком много пропусков и, по вашему мнению, это негативно скажется на качестве модели, возможно, стоит рассмотреть возможность удаления переменных или наблюдений с большим количеством пропусков. Это следует делать осознанно, учитывая потерю информации.
5. Эксперименты с моделями
Не бойтесь экспериментировать с различными подходами к обработке пропущенных данных. Настройте свои модели на использование разных методов импутации и сравните их эффективность по различным метрикам (например, точность, полнота и F1-меры). Это поможет вам выбрать наиболее подходящий метод.
6. Документируйте ваши шаги
Важно документировать, какие методы и подходы вы использовали для обработки пропущенных данных, а также результаты, которых вы достигли. Это поможет другим исследователям понять ваш процесс анализа и потенциально повторить его.
Следуя этим шагам, вы сможете более эффективно работать с отсутствующими данными и снизить риск их негативного влияния на ваши аналитические выводы.