Я запустил модель исследования лабиринта, используя DDQN, и она показала отличные результаты в процессе обучения, поэтому я хотел сохранить свою модель. Однако, когда я загрузил модель, казалось, что она никогда не проходила обучение. Я начал подозревать, что мог сохранить её неправильно. Поэтому я остановил сохранение модели и установил 500 раундов для обучения. Моя модель достигла хорошей сходимости до 400-го раунда. Итак, после 400-го раунда я прекратил вызов метода learn() и провел 100 раундов тестирования. На этом этапе параметры сети больше не должны обновляться и должны оставаться такими же, как и в 400-м раунде. Я ожидал получить хорошие результаты, но всё пошло не так, как планировалось. Вот моя диаграмма результатов ниже.
def train_maze():
step_counter = 0
global episode
saver = tf.train.Saver(max_to_keep=1) # Создаем объект Saver для сохранения модели
for episode in range(450):
RL.time = episode
total_reward = 0
observation = env.reset()
while True:
action = RL.choose_action(observation)
observation_, reward, done = env.step(action)
total_reward += reward
RL.store_transition(observation, action, reward, observation_)
if ( 3000 < step_counter <= RL.memory_size) and (step_counter % 500 == 0):
RL.learn()
elif(step_counter > RL.memory_size) and (episode <= 400) :
RL.learn()
observation = observation_
step_counter += 1
if done:
if episode <= 400:
RL._discount_and_norm_rewards()
if env.is_success:
# RL.store_fine_transition(RL.episode_memory)
if len(RL.fine_memory) > RL.batch_size :
for i in range (4):
RL.learn_fine()
else:
if len(RL.fine_memory) > RL.batch_size :
for i in range (400):
RL.learn_fine()
RL.episode_memory.clear()
RL.ep_rs.clear()
ep_total_reward.append(total_reward)
ep_total_step.append(env.ep_step)
logger.info("эпизод: {}, общее вознаграждение: {}, количество шагов в эпизоде: {}".format(episode, int(total_reward), env.ep_step))
break
Я совершенно уверен, что добавил только один раунд на основе 400 раундов, что означает, что я изменил значение эпизода только с 400 на 500, и я уверен, что моя начальная среда всегда оставалась прежней.
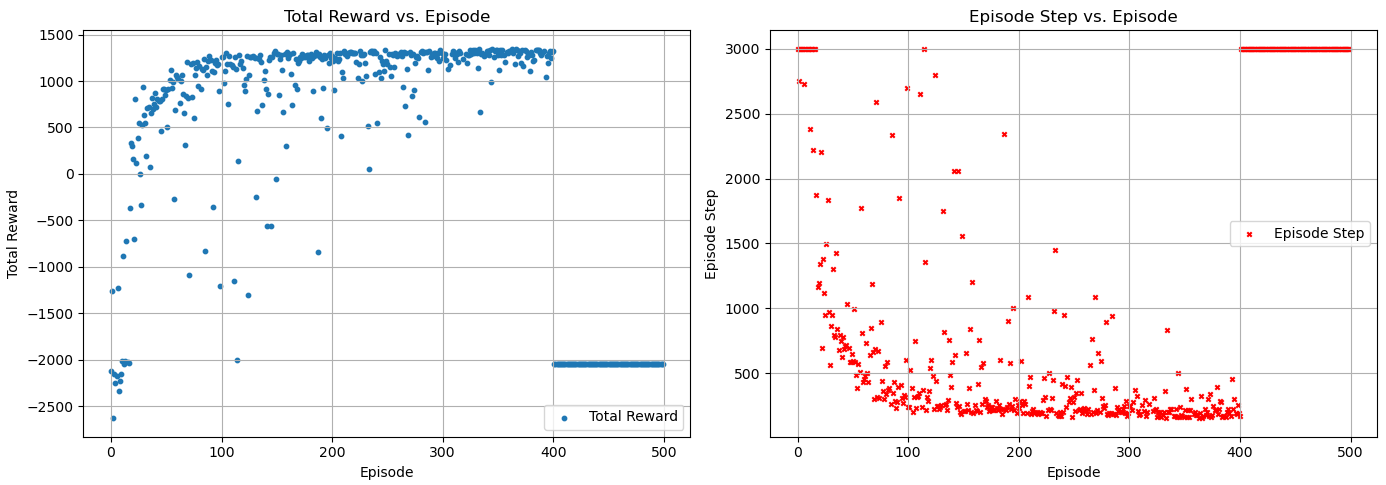
Ответ
Причины, по которым ваша модель DDQN потерпела неудачу после достижения сходимости и перехода к тестированию, могут быть связаны с несколькими факторами. Давайте разберем возможные причины и решения этой проблемы.
1. Переобучение (Overfitting)
Когда модель достигает хороших результатов на обучающих данных, но теряет производительность на тестовых данных, это может свидетельствовать о переобучении. Возможно, ваша модель научилась запоминать конкретные характеристики среды, что ухудшило её способность обобщать для новых эпизодов.
Решение: Попробуйте использовать регуляризацию, такие как Dropout или увеличение разнообразия тренировочных данных, чтобы снизить шанс переобучения.
2. Проблемы с оптимизацией
Заслуживает внимания, что модель могла отлично работать, пока происходило обучение, но последующий переход в фазу тестирования мог быть неудачным из-за неправильной настройки алгоритма оптимизации.
Решение: Убедитесь, что параметры оптимизации (например, скорость обучения и моментум) правильно настроены. Может быть полезно экспериментировать с разными значениями этих гиперпараметров.
3. Стабильность модели
Другое возможное объяснение связано с тем, как вы сохранили и загрузили модель. Если процесс сохранения модели был выполнен неправильно, это могло привести к загрузке неправильных параметров сети.
Решение: Проверьте, правильно ли вы сохранили параметры модели. Убедитесь, что сохраняете и загружаете не только веса, но и архитектуру модели. Применяйте проверенные методы сохранения (например, tf.train.Saver в TensorFlow).
4. Изменение состояния среды
Несмотря на то что вы указываете, что среда остаётся неизменной, стоит также убедиться, что состояние среды действительно одинаково между тренировочными и тестовыми эпизодами. Небольшие изменения в среде, по сути, могут вызвать сильные колебания производительности модели.
Решение: Убедитесь, что конфигурация среды действительно не изменилась между обучением и тестированием. Если возможно, фиксируйте случайные начальные состояния среды.
5. Стратегия выбора действий
Также возможно, что стратегия выбора действий во время тестирования отличается от той, что применялась во время обучения. Например, вспомогательная функция choose_action может включать случайность, которая ранее была настроена через ε-жадный метод.
Решение: В фазе тестирования проверьте, используется ли стратегия выбора действий, которая не включает случайность (например, выбирайте действие с наивысшей оценкой).
6. Ограниченное количество испытаний
100 раундов тестирования могут быть недостаточно показательным числом для полной оценки способности вашей модели. Модель может показывать хорошо результаты в зависимости от действия/состояния.
Решение: Запустите значительное количество испытаний, чтобы убедиться, что результаты являются надежными и стабильными.
Заключение
Изучите вышеперечисленные аспекты, чтобы понять поведение вашей модели. Иногда причина может быть связана с комбинацией нескольких факторов. Постарайтесь проанализировать и протестировать каждый из этих компонентов, чтобы найти источник проблемы и добиться желаемого результата.