Вопрос или проблема
Я работаю с этим CSV файлом, который представляет собой сборник детализации фильмов из IMDB.
В нем есть жанры столбец в датафрейме со всеми жанрами фильмов, разделенными символом “|”
Мне нужно извлечь первые два жанра из столбца жанры и сохранить их в двух новых столбцах: жанр_1 и жанр_2.
А для столбцов, где есть только 1 жанр, необходимо извлечь единственный жанр в оба столбца, то есть для таких фильмов жанр_2 будет таким же, как жанр_1.
Я делюсь скриншотами кода и результатов, которые я получил. 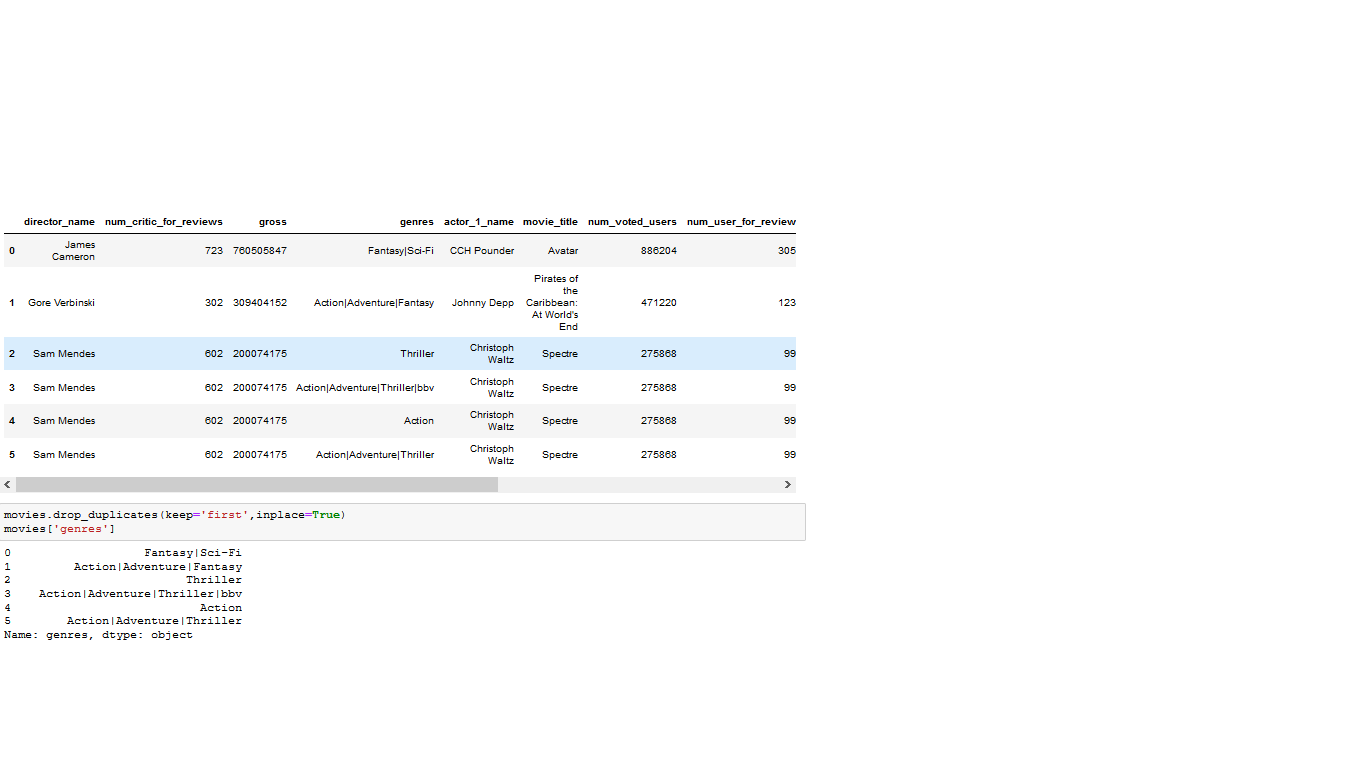
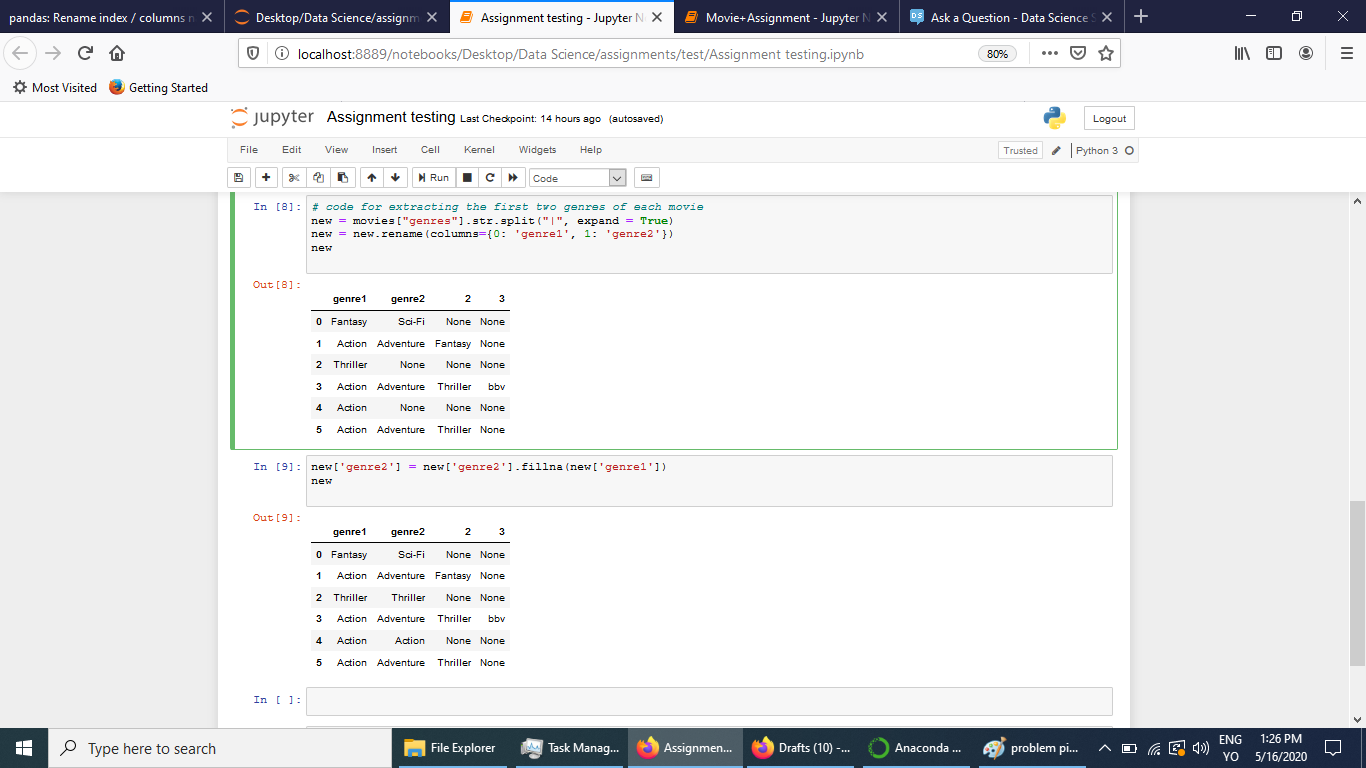
Теперь я могу создать новый датафрейм с созданными жанрами и затем удалить ненужные столбцы и объединить оставшиеся с оригинальным датафреймом. Но это выглядит довольно громоздко.
Как я могу разделить столбец в своем оригинальном датафрейме и удалить ненужные расширенные столбцы?
Буду признателен за любую помощь.
Это вопрос программирования, а не вопрос науки о данных.
Вам нужно использовать apply с функцией lambda. Так что если ваш DataFrame называется movies:
В apply вы должны добавить axis=1, что означает, что вы применяете функцию к строкам, а не к столбцам.
def get_genre(row, genre_index):
array_genres = row['genres'].split('|')
if len(array_genres) == 0:
return ''
elif len(array_genres) == 1 and genre_index == 1:
return array_genres[0]
else:
return array_genres[genre_index]
movies['genre_1'] = movies.apply(lambda row: get_genre(row, 0), axis=1)
movies['genre_2'] = movies.apply(lambda row: get_genre(row, 1), axis=1)
Попробуйте:
# Создадим пример датафрейма
df = pd.DataFrame({"genres":["Фантастика|Научная фантастика",
"Экшн|Приключения|Фантастика",
"Триллер",
"Экшн|Приключения|Триллер|bbv","Экшн","Экшн|Приключения|триллер"]})
# Получите датафрейм с таким количеством столбцов, сколько жанров
df = df.genres.str.get_dummies(sep = "|")
# Получите жанры как значения
df = df.multiply(df.columns)
# Переименуйте столбцы, чтобы получить id жанра
df.columns = ["жанр_" + str(x) for x in range(len(df.columns))]
Входные данные:
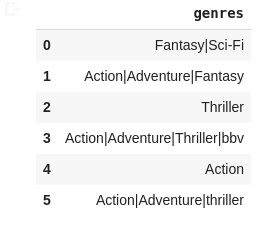
Выходные данные:
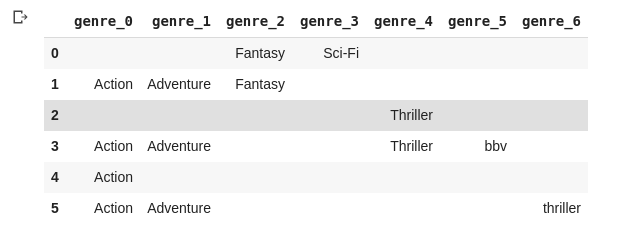
ИСПРАВЛЕНИЕ:
вы можете просто использовать метод assign библиотеки pandas:
df.assign(genre1= df.genres.str.split("|", expand = True).iloc[:,:1],
genre2 = df.genres.str.split("|", expand = True).iloc[:,1:2])
*Выходные данные:
Ответ или решение
Извлечение жанров из столбца DataFrame в Python с использованием Pandas
Работа с CSV-файлами, содержащими коллекцию данных, популярных в киноиндустрии, таких как IMDb, часто предполагает необходимость обработки данных в рамках определённых требований. В частности, если у вас есть столбец genres, в котором жанры фильмов разделены символом вертикальной черты (|), это может потребовать извлечения первых двух жанров и сохранения их в отдельных столбцах (genre_1 и genre_2). В данной статье мы рассмотрим, как это сделать, используя библиотеку Pandas в Python.
Обзор задачи
Мы имеем DataFrame с колонкой жанров, которая может содержать от одного до нескольких жанров, разделённых символом |. Нам необходимо:
- Создать два новых столбца:
genre_1иgenre_2. - Для фильмов с одним жанром заполнить оба столбца одним и тем же значением.
- В случае наличия нескольких жанров извлечь только первые два.
Решение с использованием Pandas
Для выполнения данной задачи мы можем использовать метод apply вместе с лямбда-функцией для построчной обработки элементов DataFrame. Вот пример реализации:
import pandas as pd
# Пример DataFrame
df = pd.DataFrame({"genres": [
"Fantasy|Sci-Fi",
"Action|Adventure|Fantasy",
"Thriller",
"Action|Adventure|Thriller|bbv",
"Action",
"Action|Adventure|Thriller"
]})
# Определим функцию для извлечения жанров
def extract_genres(genres):
genre_list = genres.split('|')
# Если жанров нет, возвращаем пустую строку
if len(genre_list) == 0:
return '', ''
elif len(genre_list) == 1:
# Если только один жанр, дублируем его
return genre_list[0], genre_list[0]
else:
# Если больше одного жанра, возвращаем первые два
return genre_list[0], genre_list[1]
# Применим функцию к DataFrame
df['genre_1'], df['genre_2'] = zip(*df['genres'].apply(extract_genres))
# Выводим результирующий DataFrame
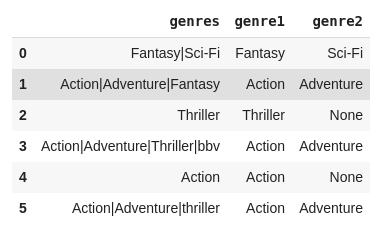
print(df)Результат
После выполнения кода выше, ваш DataFrame будет выглядеть следующим образом:
genres genre_1 genre_2
0 Fantasy|Sci-Fi Fantasy Sci-Fi
1 Action|Adventure|Fantasy Action Adventure
2 Thriller Thriller Thriller
3 Action|Adventure|Thriller|bbv Action Adventure
4 Action Action Action
5 Action|Adventure|Thriller Action AdventureИспользование методов Pandas для удобства
Чтобы избежать создания лишних столбцов и сделать код более читабельным, вы также можете воспользоваться методом assign вместе с str.split. Вот другой подход решения нашей задачи:
# Использование assign для создания новых столбцов
df = df.assign(
genre_1=df['genres'].str.split('|').str[0],
genre_2=df['genres'].str.split('|').str[1].fillna('')
)
# Дублирование genre_1 в genre_2 для случаев с единственным жанром
df['genre_2'] = df.apply(lambda x: x['genre_1'] if x['genre_2'] == '' else x['genre_2'], axis=1)
# Выводим результирующий DataFrame
print(df)Этот метод более лаконичен и позволяет избежать излишне сложных манипуляций с данными.
Заключение
В завершающей части нашей статьи мы рассмотрели два способа извлечения жанров из столбца DataFrame в Python с использованием библиотеки Pandas. Первый способ демонстрирует мощность метода apply, в то время как второй способ использует встроенные функции Pandas для достижения более чистого и понятного кода. Эти техники могут быть полезны не только при работе с данными о фильмах, но и в других сценариях обработки данных, где необходима предобработка строковых значений.