Вопрос или проблема
Учитывая, что мы обучили нашу модель на большом объеме данных для предсказания “много к одному”. Теперь мы хотели бы прогнозировать будущие данные на следующие 10 дней. Для этого мы используем последние 60 существующих данных и предсказываем одно следующее значение. Отсюда возникают 2 подхода:
-
Мы можем поместить нашу функцию
model.predict()в циклforна 10 итераций и делать предсказания таким образом (добавляя наши предсказания в конец наших реальных данных). -
Мы можем поместить всю нашу модель (состоящую из обучающей части, а не только из части предсказания) в цикл
for, и это означает, что мы обучаем нашу модель 10 раз каждый раз, когда делаем новое предсказание и добавляем его в наши реальные данные.
ИЗМЕНЕНИЕ:
Предположим, что у вас есть массив X_train = (100,60,1), который означает 100 примеров, 60 временных шагов (скрытых единиц) и 1 признак для каждого примера. Также у вас есть массив y_train размером (100,1,1), который означает 100 меток с временными шагами = 1 и 1 признак. Затем вы обучаете свою сеть читать 60 входных данных и предсказывать следующий выход. Также вы создаете массив X_test следующим образом: X_test = X_train[len(X_train - 60):], что означает, что вы используете последние 60 чисел из вашей серии для предсказания следующего числа. Итак, вы используете new_number = model.predict(X_test) для этого, и вы предсказываете временной шаг 61, который не является реальным числом. Это ваше предсказание. Затем вы хотите продолжить свои прогнозы. Так что вы добавляете предсказанное число 61 к концу вашего X_test = np.append(X_test, new_number) и снова делаете new number = model.predict(X_test). Но отличие в том, что последнее число в вашем новом X_test является вашим предыдущим предсказанием. И вы продолжаете так делать 10 раз, чтобы предсказать 10 следующих чисел. (Это был первый подход).
Другой подход (2) отличается. После выполнения new_number = model.predict(X_test) в первый раз, вы добавляете предсказанное число в x_train вместо X_test, вот так X_train = np.append(X_train, new_number) и снова обучаете свою модель model.fit(X_train , y_train) с новым предсказанным числом. Затем вы используете new number = model.predict(X_test) и снова добавляете предсказанное число в X_train, затем снова обучаете свою модель (на этот раз с 2 новыми предсказанными числами, которые вы добавили в конец вашего X_train) и так далее 10 раз!
Вы хотите сказать, что хотите предсказать на 10 дней вперед в данном случае?
Если это так, модель LSTM может это сделать, и итерация таким образом, как вы предлагаете, не требуется и может дать вам ненадежные результаты.
Например, рассмотрим набор данных, в котором мы пытаемся предсказать шаг вперед:
# Разделение данных на обучающие и тестовые
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# преобразование в X=t и Y=t+1
previous = 1
X_train, Y_train = create_dataset(train, previous)
X_test, Y_test = create_dataset(test, previous)
# переобразование входных данных в [образцы, временные шаги, признаки]
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
X_test = np.reshape(X_test, (X_test.shape[0], 1, X_test.shape[1]))
# Генерация LSTM сети
model = Sequential()
model.add(LSTM(4, input_shape=(1, previous)))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
model.fit(X_train, Y_train, epochs=100, batch_size=1, verbose=2)
# Генерация предсказаний
trainpred = model.predict(X_train)
testpred = model.predict(X_test)
# Преобразование предсказаний обратно в нормальные значения
trainpred = scaler.inverse_transform(trainpred)
Y_train = scaler.inverse_transform([Y_train])
testpred = scaler.inverse_transform(testpred)
Y_test = scaler.inverse_transform([Y_test])
# расчет RMSE
trainScore = math.sqrt(mean_squared_error(Y_train[0], trainpred[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(Y_test[0], testpred[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
В этом кусочке кода, вы можете видеть, что мы установили параметр previous равным 1, что означает, что временной шаг, рассматриваемый моделью, равен t-1.
В данном случае, вот предсказания для обучения и тестирования по сравнению с реальной серией:
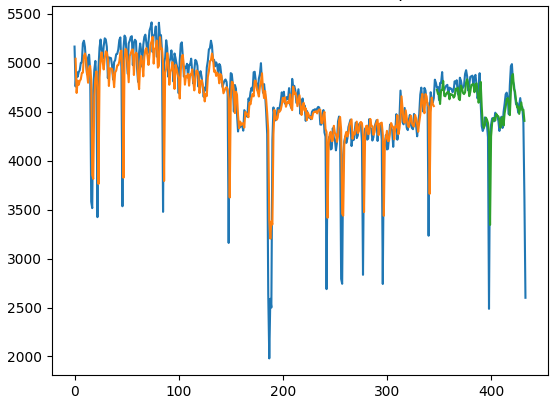
Теперь та же модель запускается, но на этот раз параметр previous установлен на 10. Другими словами, предыдущие 10 дней рассматриваются как один временной шаг, и модель прогнозирует для времени t+10 в данном случае. Вот еще одно предсказание, сравнивающее тестовый набор с действительным. Более полный пример этого можно найти здесь:
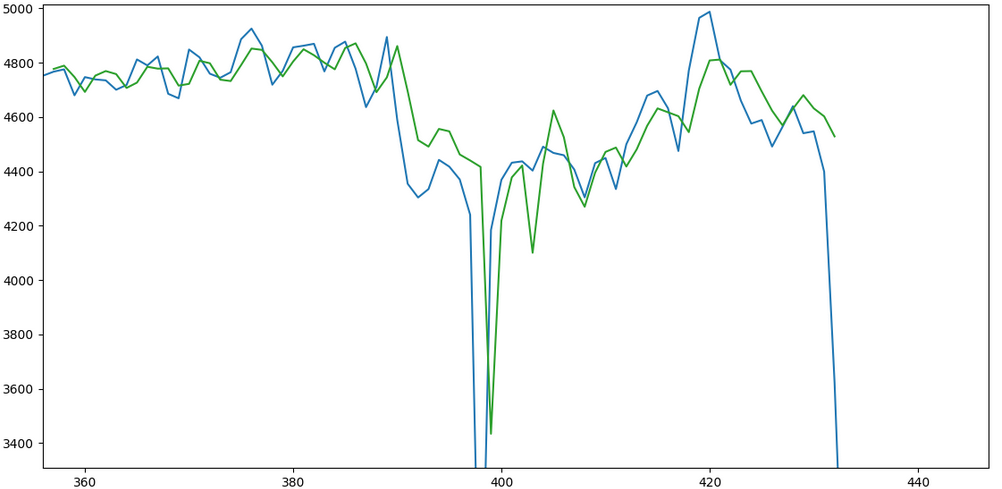
В этом отношении мой совет заключается в том, чтобы определить временной ряд, который вы хотите спрогнозировать, а затем работать на этой основе. Использование итераций только усложняет ситуацию и может даже вызвать проблемы с предсказанием.
Ответ или решение
Добавление предсказаний к реальным данным для новой тренировки и прогнозирования в LSTM: стоит ли это делать?
Введение
В современных задачах прогнозирования временных рядов модели на основе долгосрочной памяти (LSTM) получили широкое применение из-за своей способности учитывать временные зависимости в данных. Однако, когда дело доходит до методов предсказания, такие как добавление предсказанных значений в обучающую выборку для дальнейшего обучения модели, важно учитывать потенциальные риски и преимущества этого подхода.
Подходы к прогнозированию
В вашем вопросе рассматриваются два основных подхода к прогнозированию на 10 дней вперед:
-
Итеративное предсказание без переобучения: предсказание одного дня осуществляется, и полученное значение добавляется к последним данным, после чего модель снова используется для предсказания следующего дня. Этот подход не включает в себя переобучение модели после каждого предсказания.
-
Итеративное предсказание с переобучением: после каждого предсказанного значения модель переобучается с использованием обновленных данных, включая все ранее полученные предсказания.
Анализ первого подхода
Первый подход имеет свои преимущества:
- Скорость: Предсказания могут выполняться довольно быстро, так как модель не требует переработки. После каждого предсказания добавляется только одно значение.
- Сложность управления: Подход более легок в реализации и не требует значительных вычислительных ресурсов.
Однако, есть важные недостатки:
- Кумулятивная ошибка: При итеративном предсказании возможна кумуляция ошибок, когда нет возможности корректировать модель, если предсказание оказалось неправильным. Каждое следующее предсказание делается на основе предыдущих, что может значительно снижать точность.
Анализ второго подхода
С другой стороны, второй подход имеет свои плюсы:
- Корректировка модели: Переобучение позволяет корректировать модель на основе новых данных, что может повысить точность предсказаний.
- Разнообразие данных: Новые предсказанные значения становятся частью обучающего набора, что может улучшать адаптивность модели к изменениям в данных.
Но здесь также существуют минусы:
- Повышенные требования к ресурсам: Повторное обучение модели для каждого нового предсказания требует значительных вычислительных ресурсов и времени.
- Риск переобучения: Постоянное добавление предсказаний может привести к переобучению модели, особенно если предсказанные значения неточные.
Рекомендации
С учетом вышеизложенного, рекомендуется использовать осторожный подход. В большинстве случаев:
- Выбор модели: Если модель LSTM уже хорошо обучена на исторических данных с учетом особенностей системы, существует вероятность, что она будет адекватно предсказывать 10 дней вперед, не прибегая к переобучению.
- Валидация: Проведение валидации на большом отрезке данных поможет оценить точность и надежность модели. Если результаты удовлетворительны, то первый подход может быть предпочтительным.
- Тестирование на малом количестве данных: Если все же решено использовать второй подход, рекомендуется предварительно протестировать его на ограниченных наборах данных, прежде чем применять его на больших объемах.
Заключение
Добавление предсказанных значений к реальным данным для новой тренировки и предсказания в модели LSTM может быть как хорошей, так и плохой идеей, в зависимости от контекста и целей прогнозирования. Использование первого подхода может быть более целесообразно с точки зрения времени и вычислительных ресурсов, но важно помнить о возможности накопления ошибок. Второй подход с переобучением может быть полезен для улучшения точности, но требует больше ресурсов и может вызвать риск переобучения. Рекомендуется проводить дополнительные эксперименты и валидацию для выбора наиболее подходящей стратегии.