Вопрос или проблема
Я новичок в Python/Pandas, и у меня возникают некоторые трудности.
У меня есть DataFrame с данными о качестве воздуха с 2016 по 2020 год. Я хочу рассчитать годовой темп изменения для каждого измеряемого значения, чтобы сравнить их с прошлогодним значением в тот же день и месяц.
Это первые строки DataFrame.
Дата Страна Город Вид счет мин макс медиана дисперсия
0 2020-02-23 CR Сан-Хосе pm25 20 13.0 53.0 25.0 1232.00
1 2020-04-04 CR Сан-Хосе pm25 23 17.0 57.0 38.0 1302.57
2 2020-04-24 CR Сан-Хосе pm25 23 30.0 80.0 59.0 1966.13
3 2020-01-14 CR Сан-Хосе pm25 24 13.0 34.0 21.0 379.55
4 2020-02-07 CR Сан-Хосе pm25 23 57.0 95.0 72.0 838.97
У кого-нибудь есть идеи, как мне поступить?
Для ответа я делаю предположение:
- В DataFrame есть одна строка для каждой даты в прошедшие годы
Установите Дата в качестве индекса для DataFrame
df_dateInx = df.set_index('Дата')
Теперь вы можете получить строку для конкретной даты, используя следующий код
df_row = df_dateInx.loc['2018-07-15']
Добавьте новый столбец в DataFrame ‘ChangePercent’ в конце
#df_dateInx.insert(индекс_вставки, название_столбца)
df_dateInx.insert(df_row.shape[1], 'ChangePercent', True)
Создайте функцию для расчета разницы относительно значения за предыдущий год в тот же день и месяц. Эта функция будет вызываться для каждой строки DataFrame
def calChange(row):
change = 0
val_prev_yr = df_dateInx.loc[row.Date - 1]['мин']
val_this_row = row['мин']
# сделайте что-нибудь со значениями и верните change
return change
П.С. row.Date - 1 используйте функцию strptime для даты/времени, чтобы сделать это
П.С. Если есть несколько строк одной и той же даты, используйте df_dateInx.loc[row.Date - 1]['мин'][0], где [0] означает выбор первой строки из нескольких строк с одной и той же датой
Вызовите вышеупомянутую функцию для каждой строки DataFrame
df_dateInx.agg([calChange])
И вы получите DataFrame, который содержит значения в столбце Change в соответствии с вашими потребностями
Попробуйте:
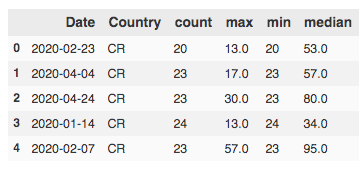
# Игровой набор данных:
air = pd.DataFrame({"Дата":["2020-02-23","2020-04-04","2020-04-24","2020-01-14","2020-02-07"],
"Страна":["CR","CR","CR","CR","CR"],
"счет":[20,23,23,24,23],
"макс":[13.0,17.0,30.0,13.0,57.0 ],
"мин":[20,23,23,24,23],
"медиана":[53.0,57.0,80.0,34.0,95.0]})
Ввод:
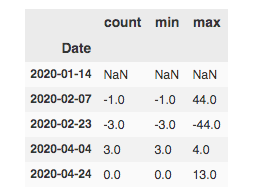
# Столбец индекса должен быть формата datetime, поэтому
air["Дата"] = pd.to_datetime(air["Дата"])
# Группировка по годам
air.set_index("Дата").groupby(pd.Grouper(freq = "y"))[["счет","мин","макс"]].diff()
Вывод:
Ответ или решение
Чтобы добавить вычисляемый столбец в DataFrame Pandas и рассчитать годовой темп изменения для данных о качестве воздуха за период с 2016 по 2020 год, мы пройдем через несколько шагов. Давайте рассмотрим, как это сделать, используя предоставленную информацию и шаги по решению вашей задачи.
Шаг 1: Установка и подготовка среды
Перед началом убедитесь, что у вас установлен Pandas. Вы можете установить его с помощью pip:
pip install pandasШаг 2: Импорт необходимых библиотек
Импортируем Pandas и создадим исходный DataFrame на основе ваших данных:
import pandas as pd
# Создаем исходный DataFrame
data = {
"Date": ["2020-02-23", "2020-04-04", "2020-04-24", "2020-01-14", "2020-02-07"],
"Country": ["CR", "CR", "CR", "CR", "CR"],
"City": ["San José", "San José", "San José", "San José", "San José"],
"Specie": ["pm25", "pm25", "pm25", "pm25", "pm25"],
"count": [20, 23, 23, 24, 23],
"min": [13.0, 17.0, 30.0, 13.0, 57.0],
"max": [53.0, 57.0, 80.0, 34.0, 95.0],
"median": [25.0, 38.0, 59.0, 21.0, 72.0],
"variance": [1232.00, 1302.57, 1966.13, 379.55, 838.97],
}
df = pd.DataFrame(data)Шаг 3: Преобразование даты и установка индекса
Настроим столбец ‘Date’ как индекс DataFrame для удобной обработки:
df["Date"] = pd.to_datetime(df["Date"])
df.set_index("Date", inplace=True)Шаг 4: Вычисление годового изменения
Для расчета изменения годового показателя по данным за каждый год мы воспользуемся методом shift() вместе с функцией groupby(), чтобы обработать данные по годам. Ниже приведён полный код расчёта:
# Группируем по году и находим разницу значений min по годам
df['ChangePercent'] = df['min'].groupby([df.index.year]).transform(lambda x: x.pct_change(periods=1))
# Вводим колонку, чтобы видеть изменения на основе предыдущего года
df['AnnualChange'] = df['ChangePercent'] * 100Шаг 5: Проверка результатов
После добавления новых столбцов, вы можете вывести DataFrame, чтобы убедиться в корректности вычислений:
print(df)Шаг 6: Обработка ошибок и Nuances
-
Проверка на NaN: В результате
pct_change()для первого наблюдения (например 2016) вы можете получить NaN, так как нет предыдущего года для сравнения. Учтите это в анализе. -
Учет дубликатов: Если у вас есть несколько записей на одну и ту же дату, вам нужно будет обработать их, например, путём группировки и усреднения значений.
-
Формат представления: Убедитесь, что у вас правильный формат для вывода, особенно для столбцов с процентами.
Заключение
В данной статье мы рассмотрели, как добавить вычисляемый столбец в DataFrame Pandas для расчета годового изменения значений за определенный период. Вычисление изменений позволяет лучше анализировать данные о качестве воздуха и способствует более глубокому пониманию изменений во времени.
Если у вас возникнут дополнительные вопросы или потребуется уточнение, не стесняйтесь обращаться за помощью.