Вопрос или проблема
Я пытаюсь добавить функцию arctan2 в конец модели Keras, но похоже, что она даже близко не подходит к локальному минимуму. Вот мой смешной, но минимальный работающий код с использованием функции Add() из Keras вместо функции arctan2:
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as ss
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv1D, Add
import tensorflow as tf
kernel_size = 64
epochs = 1000
def atan2(tensors):
Q = tensors[0]
I = tensors[1]
return tf.math.atan2(Q, I)
def atan2_output_shape(input_shapes):
return tuple(input_shapes[0])
atan2_layer = Lambda(atan2, output_shape=atan2_output_shape)
## Генерация данных для обучения
x_train = np.random.randn(1024, 512)
t = np.linspace(0, x_train.shape[1], x_train.shape[1], endpoint=False)
sine = np.sin(2*np.pi*t/32)
cosine = np.cos(2*np.pi*t/32)
x_I = np.multiply(x_train, cosine)
x_Q = np.multiply(x_train, sine)
b_I = ss.tukey(kernel_size)
b_Q = ss.tukey(kernel_size)
x_I_filt = np.array([np.convolve(b_I, x_I_i, mode="valid") for x_I_i in x_I])
x_Q_filt = np.array([np.convolve(b_Q, x_Q_i, mode="valid") for x_Q_i in x_Q])
y_train = x_Q_filt + x_I_filt
# y_train = x_Q_filt * x_I_filt
# y_train = np.arctan2(x_Q_filt, x_I_filt)
x_I = np.expand_dims(x_I, axis=2)
x_Q = np.expand_dims(x_Q, axis=2)
y_train = np.expand_dims(y_train, axis=2)
## Модель Keras
input_I = Input(shape=(x_I.shape[1], 1))
input_Q = Input(shape=(x_Q.shape[1], 1))
conv_I_1D = Conv1D(filters=1, kernel_size=kernel_size, activation=None, padding='valid', use_bias=False)(input_I)
conv_Q_1D = Conv1D(filters=1, kernel_size=kernel_size, activation=None, padding='valid', use_bias=False)(input_Q)
out_I_Q = Add()([conv_I_1D, conv_Q_1D])
# out_I_Q = Multiply()([conv_I_1D, conv_Q_1D])
# out_I_Q = atan2_layer([conv_Q_1D, conv_I_1D])
model_1D = Model([input_I, input_Q], out_I_Q)
model_1D.compile(optimizer="sgd", loss="mean_squared_error")
history_1D = model_1D.fit([x_I, x_Q], y_train, epochs=epochs, verbose=0)
и после 100 эпох я получаю почти идеальное начальное ядро фильтра:
plt.semilogy(history_1D.history['loss'])
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
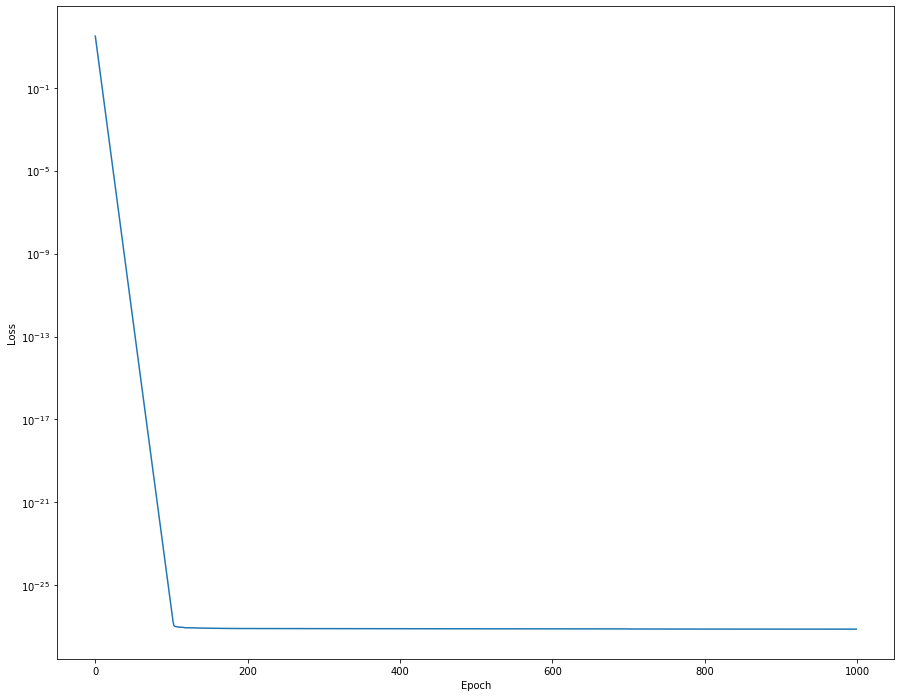
Это также хорошо работает с функцией Multiply(). Но если я заменю y_train на y_train = np.arctan2(x_Q_filt, x_I_filt) и out_I_Q на out_I_Q = atan2_layer([conv_Q_1D, conv_I_1D]), я получу этот печальный график потерь:
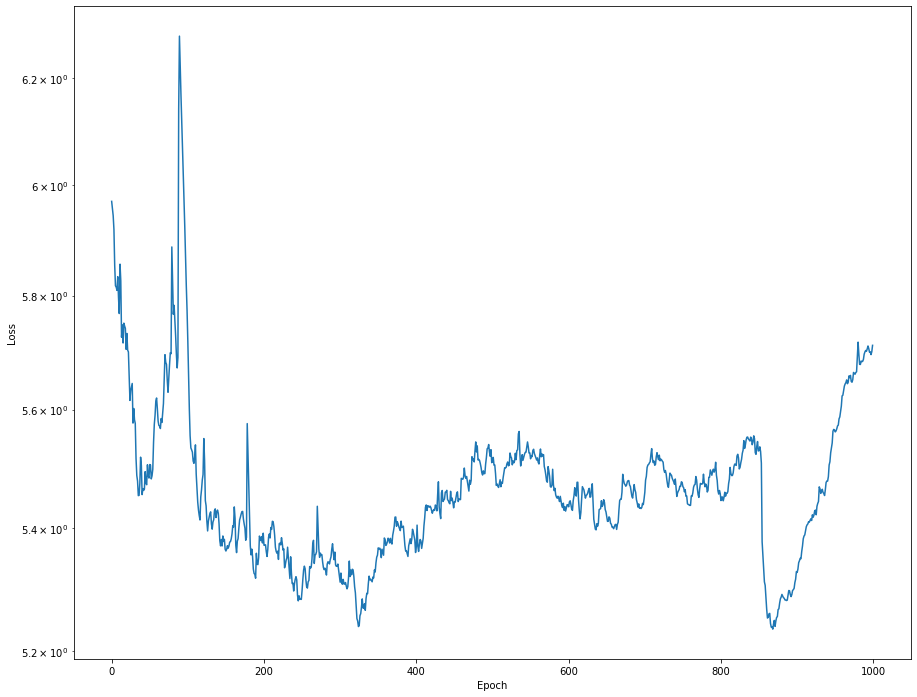
Я даже инициализирую веса, как это следует делать, но с небольшой поправкой до запуска model_1D.fit(...). b_I и b_Q – те же самые массивы.
offset = 1e-5
array_for_I_weights = np.array(model_1D.layers[2].get_weights())
array_for_I_weights[0,:,0,0] = list(b_I+offset)
model_1D.layers[2].set_weights(array_for_I_weights)
model_1D.layers[3].set_weights(array_for_I_weights)
График потерь после этапа обучения выглядит так:
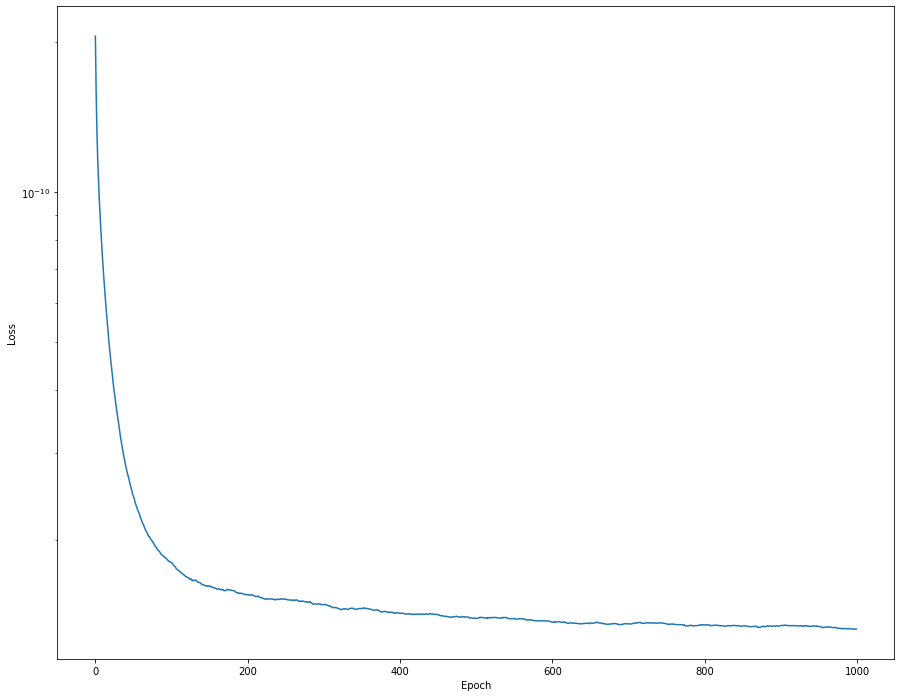
Но если я изменю offset на 1e-4, я получу такой график потерь:
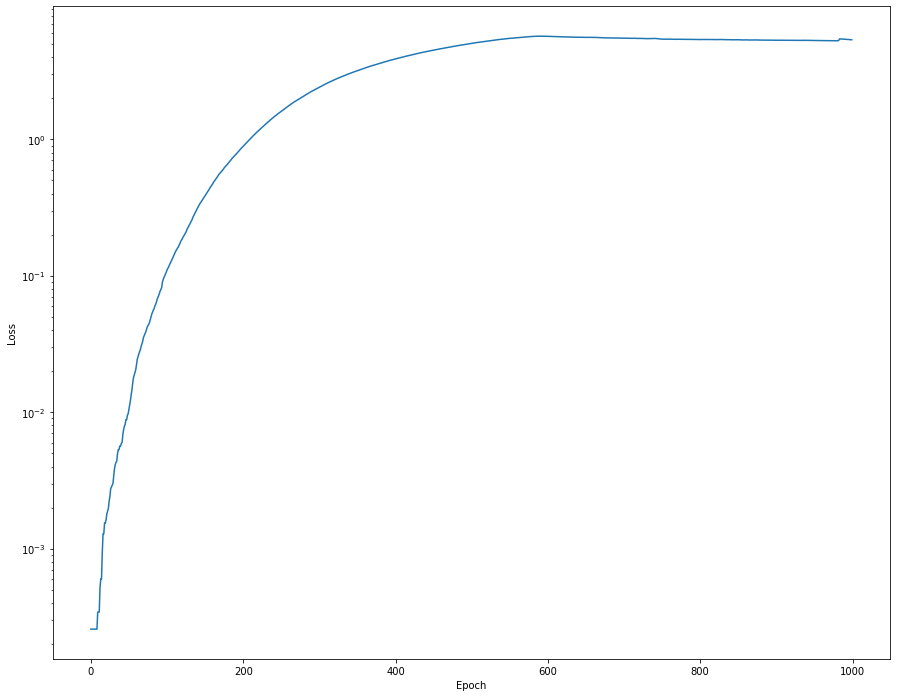
С каждым шагом становится только хуже. Что же не так с функцией arctan2 в случае её использования внутри модели Keras? Почему модель удаляется от хорошего минимального значения? Может быть, мне следует использовать другую функцию потерь/метрику?
Смена типа оптимизатора вообще не помогает. Я использую tensorflow версии 2.0 и Keras 2.2.5.
Одна из возможных проблем заключается в том, что вы переключаетесь между tf.math.atan2 и np.arctan2. Используйте только tf.math.atan2, так как эта функция разработана для работы с Keras.
Ответ или решение
Вопрос использования функции arctan2 в модели Keras требует глубокой проработки, чтобы достичь минимизации ошибки и оптимизации работы нейронной сети. Давайте рассмотрим возможные причины возникновения проблем, предложим методологический подход к их решению, а также рассмотрим примеры настройки и использования функции tf.math.atan2 в Keras.
Теория
Функция arctan2 — это важная математическая функция, которая используется для вычисления угла по заданным координатам x и y. В контексте машинного обучения и обработки сигналов эта функция может использоваться для извлечения фазовой информации из сигналов, что, в свою очередь, может быть критично для некоторых приложений, например, в радиотехнике и обработке изображений.
Использование arctan2 в Keras моделях может быть связано с рядом особенностей. В первую очередь, необходимо удостовериться, что используются корректные типы данных. TensorFlow предоставляет свою версию этой функции – tf.math.atan2, которая оптимизирована для работы с тензорами и автоматическим дифференцированием. В отличие от numpy.arctan2, которая работает с массивами numpy, TensorFlow функция поддерживает функционал, необходимый для обучения моделей, включая обратное распространение ошибки.
Одной из возможных проблем при использовании такой функции в модели является то, что arctan2 обладает разрывной характеристикой. Она обрабатывает знаки входных данных различным образом, что приводит к неочевидным изменениям градиентов, влияющим на процесс обучения.
Пример
Давайте разберёмся с вашим кодом. Мы уже заметили, что вы используете scipy.signal для генерации сигналов и свёрток, а также Keras для построения модели. Вы уже создали функцию:
def atan2(tensors):
Q = tensors[0]
I = tensors[1]
return tf.math.atan2(Q, I)Эту функцию вы передаете в слой Lambda. Этот подход корректен, однако стоит обратить внимание на детализацию и диагностику процесса обучения. Например, полезно будет изучить профиль потерь на разных фазах обучения и попробовать разное масштабирование данных перед передачей в эту функцию. Обратите внимание также на то, чтобы масштаб фильтров импульсного отклика совпадал по размерности с выходными данными.
В вашем подходе вы ставите фильтры в слои Conv1D с kernel_size=64, что отражается на форме выходных данных. Генерация ошибок может быть вызвана тем, что данные разной формы или масштаба, что может вводить дополнительные погрешности в расчётах.
Применение
Для решения вашей задачи можно опробовать следующие шаги:
-
Удостовериться, что все ваши данные нормально масштабированы. Перед добавлением слоев арктангенса данные стоит нормализовать и убедиться, что они не содержат выбросов, которые могут вносить возмущения в градиенты.
-
Экспериментировать с различными типами и архитектурами активации. Для функций, таких как
atan2, выбор функции активации может играть решающую роль. Попробуйте экспериментировать с различными параметрами и активациями, чтобы достичь более стабильной и ожидаемой сходимости. -
Проверить согласованность данных и меток. Это касается как индивидуального качества входной информации, так и самой целевой функции. Если метки (в вашем случае, данные
y_train) не согласуются с предсказаниями модели, могут возникать ошибки данных на этапе обучения. -
Обратное распространение градиента. Обратите внимание на работу модели с функцией потерь. Например, использование гладкой функции, такой как MSE, может быть менее точным, но более стабильным вариантом в сочетании с
atan2. -
Диагностика и логирование процессов. Используйте обширное логирование ошибок и промежуточных значений, чтобы отследить, на каком этапе модель начинает отклоняться от оптимума.
Заключительно, удачной практикой при решении таких задач является постепенность в изменении: вносите одну переменную за раз и оценивайте изменения в поведении модели. Это позволит отследить конкретную причину сбоев в обучении и реакции модели на изменения в архитектуре.