Вопрос или проблема
Я просмотрел презентацию Тянци Чена, но мне сложно понять детали, касающиеся весов листьев, и я был бы признателен, если бы кто-то помог прояснить это.
Чтобы выразить уравнения словами на слайде “Помещено в контекст: модель и параметры”, предсказанное значение/оценка (обозначаемая как yhat) равна сумме K деревьев модели, где каждое сопоставляет атрибуты с оценками. Пока все в порядке, думаю.

Затем на следующем слайде показан пример дерева решений, вычисляющего, насколько кому-то нравится компьютерная игра X. (Кстати, разве это не странный пример? Кому-то нравится компьютерная игра X на 2? Что это вообще значит? Почему бы не выбрать пример с более конкретным, осмысленным значением?)
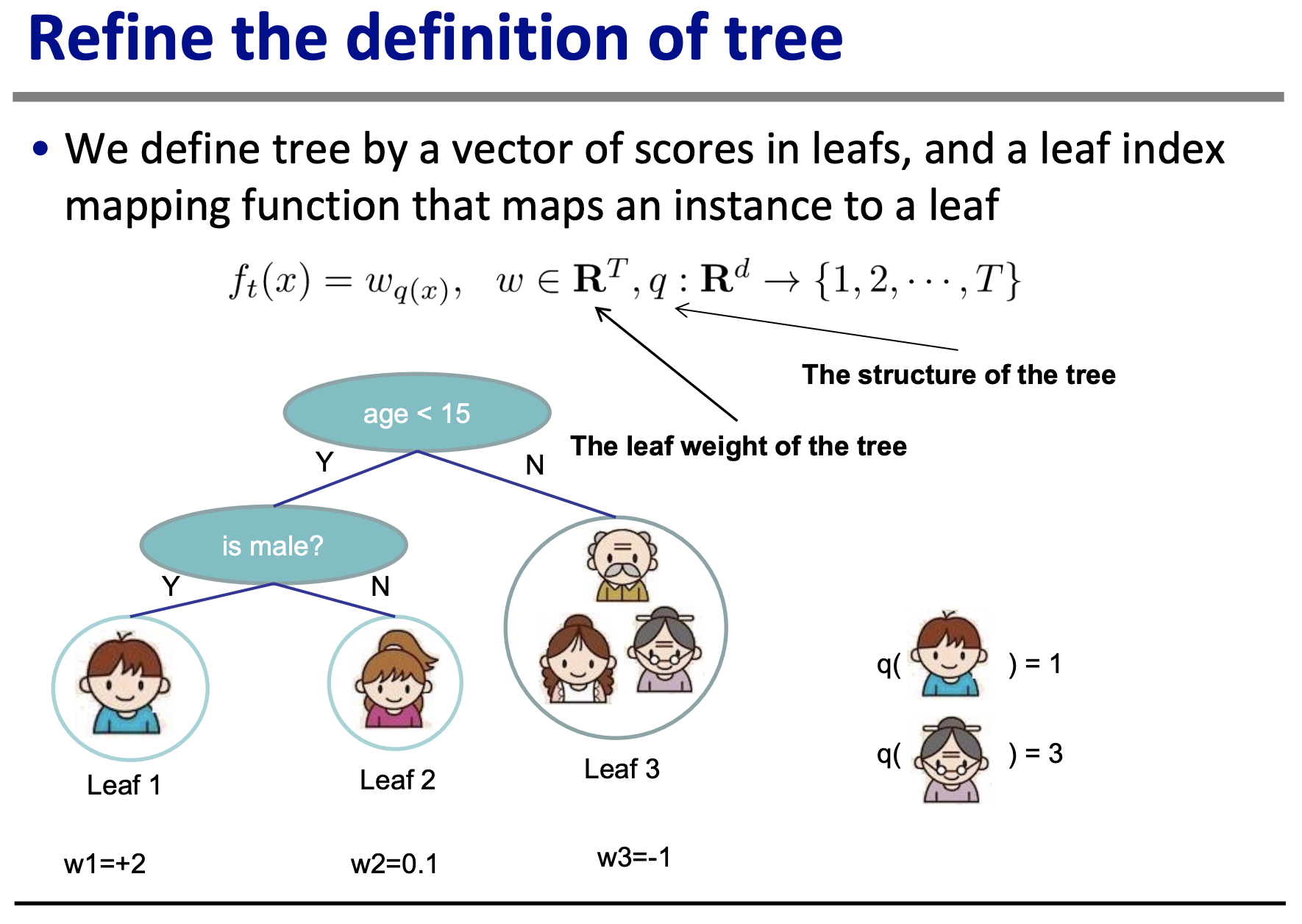
Теперь, тут я начинаю теряться. Я могу составить макетные данные для этого примера, предполагая, что модель идеальна, так что веса (w1, w2, w3) равны истинному значению. Но даже это представляется странным: в чем разница между предсказанным значением/оценкой и весами?
x_i: "атрибуты" y_i, истинная оценка (не yhat_i, который является предсказанной оценкой)
| |
|¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯|¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯|
| Возраст <15 (x_0) | мужской пол (x_1) | На сколько нравится компьютерная игра X |
| 1 | 1 | 2 | (Мальчик)
| 1 | 0 | 0.1 | (Девочка)
| 0 | 1 | -1 | (Пожилой мужчина)
| 0 | 0 | -1 | (Пожилая женщина)
| 0 | 0 | -1 | (Молодая женщина, старше 15 лет)
Мой вопрос: Может кто-нибудь поделиться, какой будет ФАКТИЧЕСКАЯ функция f? Я предполагаю, что это вектор/матрица, но каковы истинные числа? Затем мой дополнительный вопрос: как бы вы рассчитали f для этого примера? Я чувствую, что это очень просто, но не могу найти ответ. Если кто-то смог бы подробно разъяснить это, это было бы огромной помощью. Спасибо!
Я бы прочитал статью (особенно раздел 2.2) для более краткого изложения и формального определения терминов.
Вам нужно определить функцию потерь $\mathcal{L}$ для вашей задачи. Тогда $g_i$ и $h_i$ являются первой и второй производными от $\mathcal{L}$ соответственно. Оптимальные веса тогда (уравнение (5) или слайд 27).
$$
w_j^* = -\dfrac{\sum_{i \in I_j}g_i}{\sum_{i \in I_j}h_i + \lambda}
$$
где $\lambda$ — это параметр регуляризации.
Таким образом, эти веса дают минимум (второго порядка приближения) $\mathcal{L}$.
Редактировать:
Поскольку веса даны в примере, основная работа уже выполнена (см. Рисунок 1 в статье). Следуя определениям, $f =w_{q(x)}$ и $q(x)$ сопоставляет экземпляр с листовым узлом. Собрав это вместе, получаем:
$$
f = \begin{cases}
2 & \mbox{возраст} < 15 \mbox{ и } \mbox{мужской пол} \\
0.1 & \mbox{возраст} < 15 \mbox{ и } \mbox{не мужской пол} \\
-1 & \mbox{возраст} \geq 15
\end{cases}
$$
Не знаю, решила ли вы проблему или нет… но я считаю, что это фактически “выход”, а именно $f_t(x_i)$. Вы можете это увидеть, проверив уравнение (4) в их статье.
https://stats.stackexchange.com/questions/509970/are-leaf-weights-in-xgboost-equivalent-to-output-values Эта ссылка говорит то же самое.
.
Ответ или решение
Введение в XGBoost и интуитивное значение "веса листа" в контексте машинного обучения может показаться сложным, но в основе своей это понятие обладает достаточно ясной интерпретацией. Позвольте мне разложить это по частям, объясняя концепт, приводя примеры и предлагая способы его практического использования.
Теория: Что такое "вес листа" в XGBoost?
XGBoost, что расшифровывается как "Extreme Gradient Boosting", — это библиотека, созданная для реализации эффективных и высокопроизводительных градиентных бустинговых деревьев решений. Один из ключевых аспектов модели XGBoost — это структура деревьев решений, где "листья" определяют выходные значения для наблюдений, попадающих в ту или иную конечную ветку дерева.
Листья и их вес: В контексте XGBoost "лист" дерева решений — это конечный узел, в который попадает наблюдение на основе его атрибутов (например, возраст, пол и т.д.). "Вес листа" — это простое числовое значение, представляющее собой результат или предсказание, связанное с этим листом. Этот вес определяет конечный вклад листа в итоговое предсказание модели для данного набора данных.
Математическая интерпретация: Если рассмотреть вспомогательные параметры модели и основываться на функционале потерь $\mathcal{L}$, то веса листьев оптимизируются для минимизации потерь, что означает, что они являются решением уравнения минимизации потерь с использованием градиентного и второго порядка производной. В случае XGBoost, формула для оптимального веса листа выражается следующим образом:
$$
wj^* = -\dfrac{\sum{i \in I_j}gi}{\sum{i \in I_j}h_i + \lambda}
$$
здесь $g_i$ и $h_i$ — это первая и вторая производные функции потерь по предсказанию модели для $i$-го примера, $\lambda$ — параметр регуляризации, а $I_j$ — набор индексов, которые попадают в лист $j$.
Пример: Роль и расчет веса листа
Рассмотрим пример из расчета предпочтений пользователя по отношению к компьютерной игре. Здесь мы имеем данные пользователей, такие как возраст и пол, и конечная задача состоит в предсказании степени их интереса к игре. Каждый лист дерева решений назначает "вес", соответствующий предсказанию для подгруппы этих данных.
Например, в этой модели, если возраст меньше 15 и пол мужской, вес листа может составить 2, что будет конечным предсказанием интереса. В противном случае (например, возраст >= 15) вес может составить -1, указывая на меньший интерес.
Применение: Как использовать веса листьев на практике?
На практике понимание и анализ веса листьев могут помочь в интерпретации сложных моделей и в оценке важности различных фичей. Это может быть полезно, когда нужно объяснить модель заинтересованным сторонам или клиентам, которые могут не иметь технического образования. Также с помощью анализа весов возможно проводить диагностику и оптимизацию модели для повышения её точности и эффективности.
-
Интерпретация результатов: Понимание распределения весов в деревьях может предоставить ценные инсайты о том, какие атрибуты значительно влияют на предсказания и как они взаимодействуют между собой.
-
Оптимизация модели: Изучение весов может подсказывать, какие ветки деревьев неэффективны, и вместе с гиперпараметрами модели может привести к уменьшению переобучения.
-
Пояснение модели: В доступной форме объяснить, как и почему модель приняла определенные решения на основе представлений данных и весов узлов.
Подытоживая, понятие "вес листа" в XGBoost является ключевым элементом, глубоко интегрированным в механизм работы алгоритма градиентного бустинга, который позволяет не только повысить предсказательную мощность модели, но и облегчает её интерпретацию и адаптацию под конкретные задачи. Понимание этого концепта предоставляет более глубокую возможность анализа и усовершенствования предсказательных моделей в различных областях.