Вопрос или проблема
Я новичок в компьютерном зрении и обучаю нейронную сеть TensorFlow с использованием VGG16. Проблема довольно простая:
Я тренируюсь на пользовательском наборе данных для обнаружения и локализации цифр на изображении размером 100×100. Цифры (от 0 до 9) могут появляться в любых координатах x и y в пределах размера изображения 100×100. Модель работает очень хорошо, когда появляется один объект (цифра).
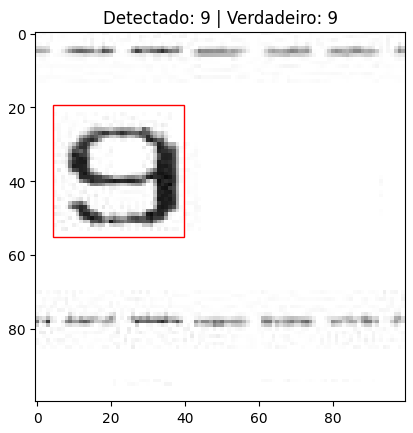
Однако, когда на изображении появляется несколько объектов, модель не может справиться с задачей.
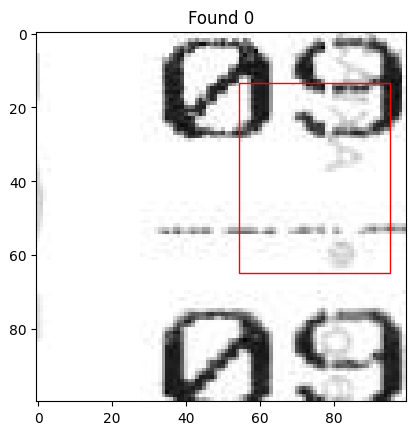
Ожидаемый результат – это нечто подобное:
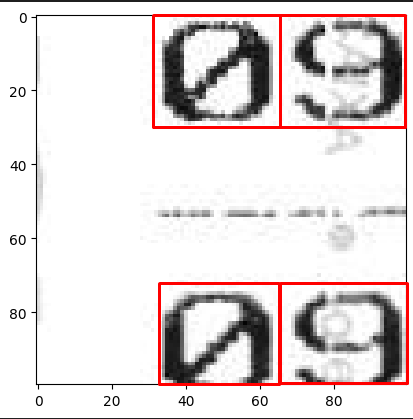
Как я могу это сделать? Проблема связана с model.predict() и тем, как я передаю изображение, но я не знаю, что делать сейчас.
Я нашел решение проблемы.
VGG не была создана для обнаружения и локализации нескольких объектов одновременно. Мы можем сделать некоторые обходные пути, чтобы заставить это работать, как я описывал ранее, но это слишком сложно и требует много вычислительных ресурсов.
Поэтому я решил перейти к использованию R-CNN и YOLO для обнаружения и локализации нескольких объектов. Эти модели предназначены для этой задачи.
Надеюсь, это поможет всем, кто столкнулся с той же проблемой, что и я.
Ответ или решение
Объектная локализация и извлечение текста с использованием VGG
В процессе работы с компьютерным зрением и обучением нейронной сети TensorFlow на базе VGG16 вы столкнулись с проблемой, когда ваша модель справляется с одиночными числами в изображениях размером 100×100, но не может эффективно обрабатывать случаи с множественными объектами. Давайте подробно разберем вашу задачу и предложим возможные решения.
Фон проблемы
Согласно вашей описании, вашей целью является детектирование и локализация чисел от 0 до 9 в изображениях, где числа могут появляться в произвольных координатах. Модель, построенная на архитектуре VGG16, показывает хорошие результаты при наличии одного объекта, однако, когда в изображении присутствует более одного числа, эффективность значительно снижается.
Это связано с тем, что VGG предназначена в первую очередь для классификации изображений и не оптимизирована для обнаружения и локализации нескольких объектов на одном изображении. Это приводит к ситуации, когда модель не может корректно обрабатывать множество объектов, так как VGG не имеет встроенных механизмов для выполнения таких задач.
Почему VGG не подходит для вашей задачи
-
Архитектура модели: VGG16 изначально разработана для классификации изображений, что делает ее менее подходящей для задач с множественными объектами. Ожидается, что модель выдаст один результат на выходе – класс объекта.
-
Отсутствие механизма региона: VGG не включает специализированные механизмы для выделения областей интереса внутри изображения, что существенно ограничивает ее способность к локализации.
-
Сложность улучшения: Хотя можно реализовать некоторые обходные пути для адаптации VGG к вашей задаче, это требует значительных вычислительных ресурсов и может быть оправдано только в редких случаях.
Варианты решения задачи
С учетом вышеизложенных недостатков, вам следует рассмотреть альтернативные архитектуры, такие как R-CNN или YOLO, которые были специально разработаны для задачи множественного обнаружения объектов и их локализации. Ниже перечислены основные преимущества этих моделей:
-
YOLO (You Only Look Once):
- Быстрота: Все объекты обрабатываются за одно проходжение через сеть, что значительно ускоряет процесс обнаружения.
- Точное местоположение: YOLO предоставляет координаты ограничивающих рамок для каждого обнаруженного объекта, что идеально соответствует вашей задаче.
-
R-CNN (Region-based Convolutional Neural Networks):
- Точность: Данная модель предоставляет высокую точность для локализации множества объектов на изображении.
- Гибкость: Позволяет адаптироваться к разным задачам и типам данных.
Заключение
Использование VGG16 для задачи множественного обнаружения объектов и локализации является не самым оптимальным решением. Однако вы правильно определили проблему и перенаправили усилия на более подходящие архитектуры, такие как R-CNN и YOLO. Эти технологии значительно упростят задачу извлечения текста и детектирования объектов на ваших изображениях.
Такой подход не только сэкономит ваше время, но и обеспечит качественные результаты, что является важным аспектом в сфере компьютерного зрения. Если у вас возникнут дополнительные вопросы по применению упомянутых моделей или по их интеграции в ваши проекты, не стесняйтесь обращаться за помощью.