Вопрос или проблема
Когда я обучаю нейронную сеть, я понимаю ценность нормализации входных данных до значения средней = 0 и стандартного отклонения = 1 (стандартизации данных). Но я часто вижу, что люди делают данные еще более “нормальными”, трансформируя их так, чтобы их форма лучше соответствовала нормальному распределению, а не только метрикам средней и стандартного отклонения.
Я надеюсь, кто-то сможет помочь мне понять это, я попробовал ниже проиллюстрировать, где возникает недопонимание.
Если у меня есть признак, который я знаю следует распределению Вейбулла, его функция плотности может выглядеть примерно так (лямбда = 1, k = 1.5):
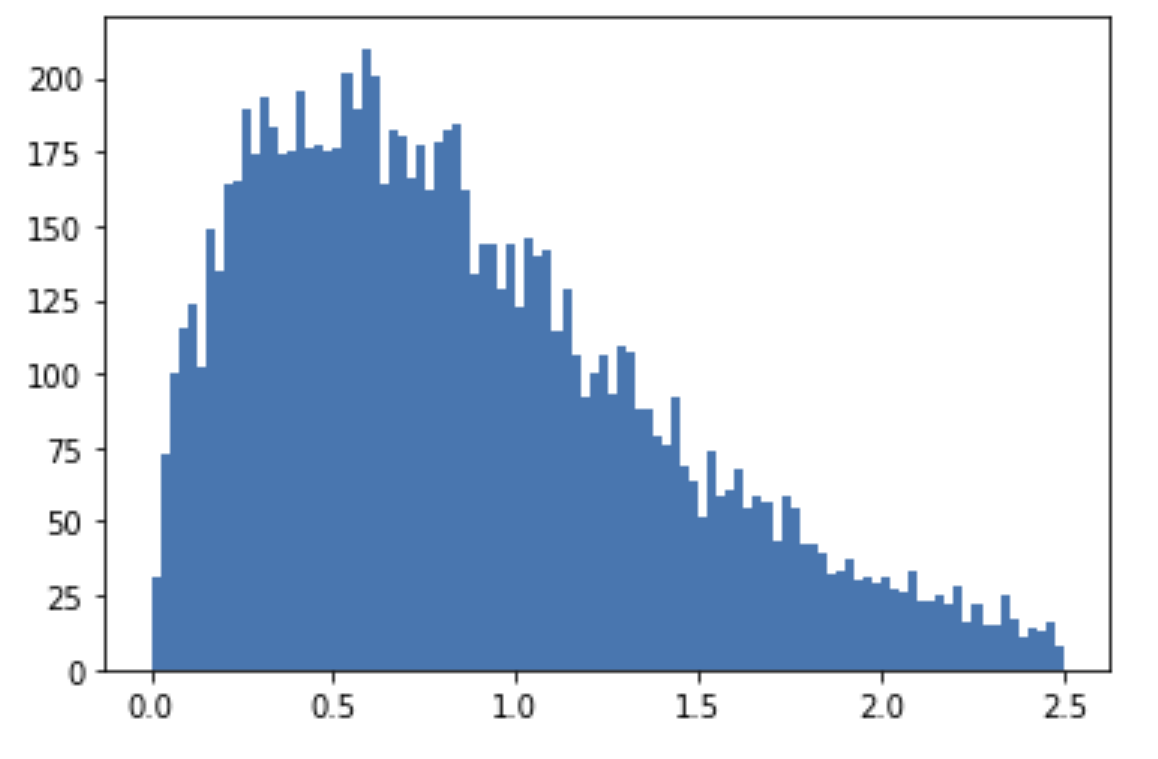
(Я просто разбил данные, чтобы показать форму плотности).
Затем я стандартизирую данные так, чтобы средняя = 0 и стандартное отклонение = 1, и мы получаем плотность, которая выглядит так:
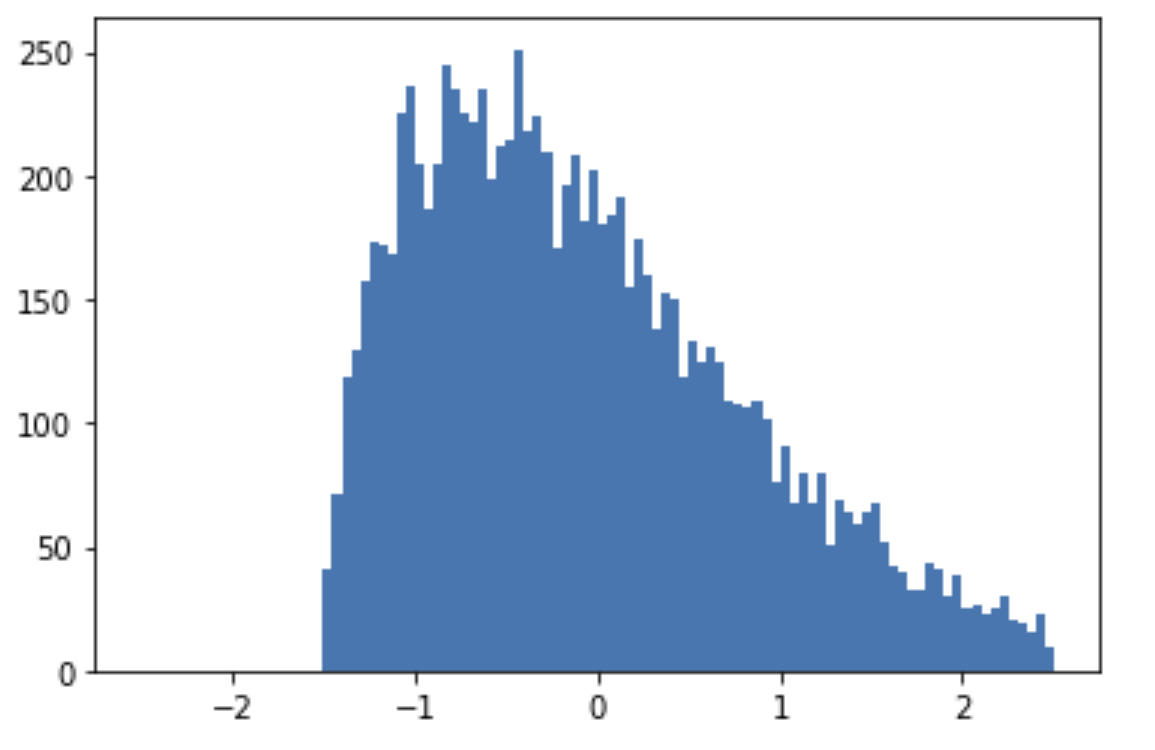
Здесь я бы остановился с предобработкой и тут я становлюсь озадаченным. Почему часто рекомендуется идти еще дальше и трансформировать распределение, чтобы его форма соответствовала нормальному распределению. Это приводит к плотности, которая выглядит так:
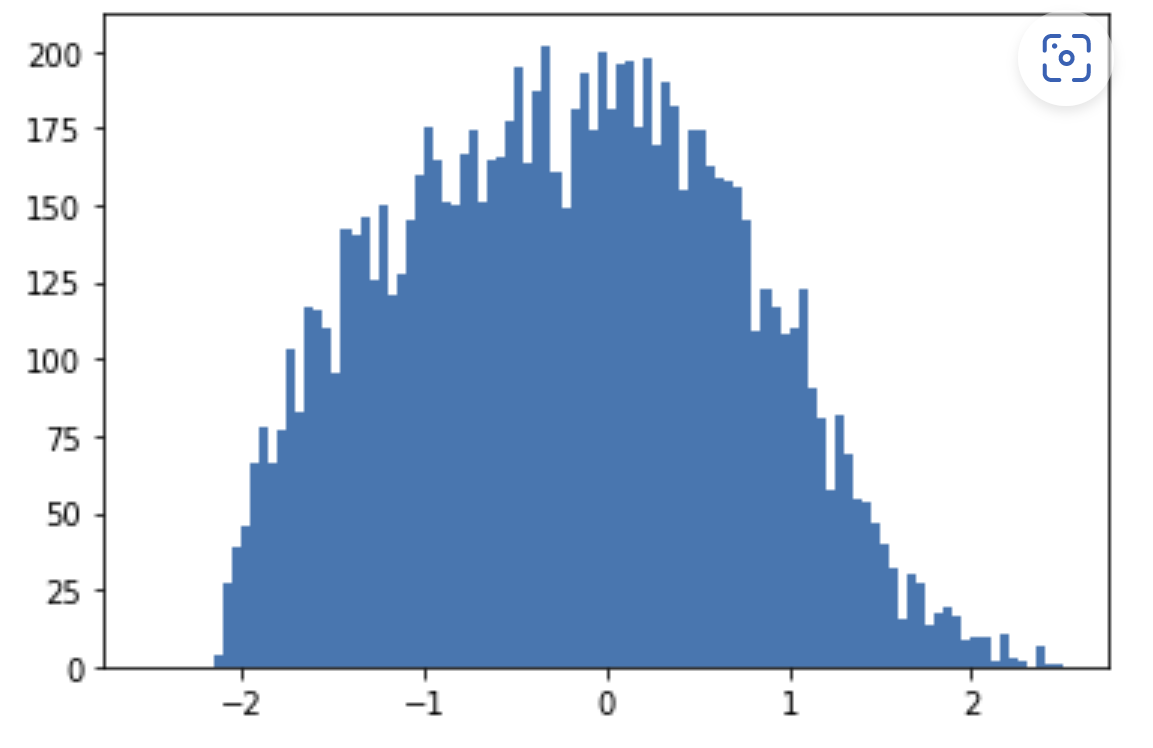
Интуитивно мне кажется, что мы теряем некоторую информацию, изменяя распределение, если кто-то может объяснить, где моя интуиция неверна, я был бы очень признателен.
Также, мне кажется, что есть большой недостаток в изменении распределения признака, что, вероятно, является просто еще одним моим недопониманием. Недостаток, который я вижу, заключается в том, что если мы знаем, что данные склоняются к низким значениям (как распределение Вейбулла с лямбда = 1, k = 1.5), то, конечно же, мы хотим обучить модель больше на этих низких значениях, которые модель, как только будет обучена и работать в реальном времени, будет чаще видеть. Разве нас не интересует больше то, как модель работает на этих низких значениях, чем на высоких?
Цель стандартизации заключается в том, чтобы значения признаков были сопоставимы. Например, в предсказании стоимости жилья количество комнат и размер дома очень различаются, и нам необходимо нормализовать их перед тем, как они будут поданы в сеть. Если вы не нормализуете, влияние размера дома будет значительно больше, чем количество комнат. Вы правы, что нам нужно привести диапазон значений в сопоставимый вид, однако совершенно не обязательно приводить его к нормальному распределению. Вы также правы, что это приведет к потере информации, надеюсь, это поможет.
Ответ или решение
Насколько "нормальными" должны быть мои входные данные?
Контекст
При обучении нейронных сетей важна предварительная обработка данных. Часто используемым методом является нормализация данных, при которой данные получают среднее значение = 0 и стандартное отклонение = 1. Однако встречается рекомендация делать данные еще более "нормальными", приводя их распределение к нормальному. Рассмотрим, когда такой подход целесообразен, а когда может вызвать потери информации.
Зачем стандартные методы нормализации?
Нормализация данных включает два основных аспекта:
- Стандартизация помогает устранить дисбаланс в масштабе различных переменных, что важно, например, в задачах прогнозирования цен на жилье, где количество комнат и площадь могут быть в разных масштабах.
- Централизация обеспечивает сходимость моделей быстрее и устойчивее к локальным минимумам.
Преимущества и недостатки приведения распределения к нормальному
Преимущества:
- Улучшение сходимости: Нейронные сети могут сходиться быстрее, если входные данные близки к нормальному распределению.
- Методологические соображения: Некоторые модели предполагают нормальное распределение данных как допущение.
Недостатки:
- Потеря информации: Трансформации, направленные только на приведение к нормальному распределению, могут стереть особенности, важные для модели. Например, асимметрия в распределении, как в случае с распределением Вейбулла, может быть критическим фактором для решения задачи.
- Потенциальная избыточность: Не все алгоритмы требуют нормального распределения; многие современные архитектуры глубокого обучения, такие как свёрточные или рекуррентные нейронные сети, могут справляться с разнообразными распределениями данных.
Заключение
Основная цель нормализации — сделать данные сопоставимыми и облегчить обучение моделей. Приведение распределения к нормальному является продвинутой техникой и должно использоваться с пониманием специфики задачи и её требований. Важно помнить, что консистентность и соотнесённость с реальными данными имеет первостепенное значение — то, что вы потеряете в процессе лишней трансформации, может быть критично для вашего конечного решения.
Оптимальный совет: Прежде чем трансформировать данные в сторону нормального распределения, рассмотрите возможность применения методов без потери важной информации, таких как робастные модификации, асимметричные функции потерь и интеллектуальные архитектуры нейронных сетей.
Надеюсь, это объяснение поможет вам лучше понять баланс между нормализацией и сохранением важной информации в данных.