Вопрос или проблема
Я использую TFBertForSequenceClassification от Huggingface для многометок «классификации твитов». Во время обучения модель достигает хорошей точности, но точность на валидации низкая. Я пытался решить проблему переобучения, использовав дроп-аут, но производительность все равно остается низкой. Модель выглядит следующим образом:
# Получить и настроить модель BERT
config = BertConfig.from_pretrained("bert-base-uncased", hidden_dropout_prob=0.5, num_labels=13)
bert_model = TFBertForSequenceClassification.from_pretrained("bert-base-uncased", config=config)
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=0.00015, clipnorm=0.01)
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.CategoricalAccuracy('accuracy')
bert_model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
bert_model.summary()
Резюме выглядит следующим образом:
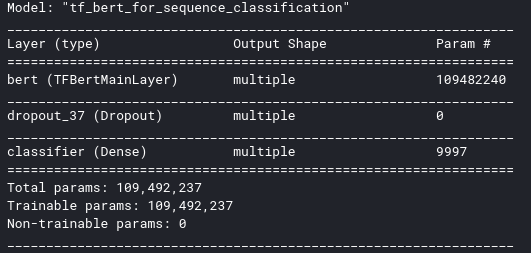
Когда я обучаю модель, результат следующий:
history = bert_model.fit(train_ds, epochs=30, validation_data = test_ds)
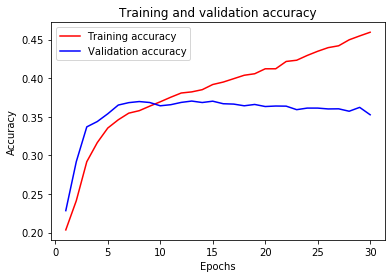
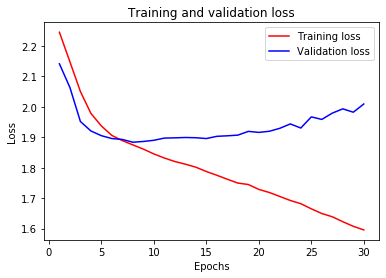
По моему опыту, лучше создать свой собственный классификатор, используя модель BERT и добавив 2-3 слоя к модели для целей классификации. Встроенный классификатор настроения использует только один слой. Но для лучшей генерализации ваша модель должна быть глубже с правильной регуляризацией. Поскольку у вас около 13 классов, следует использовать более глубокую модель с хорошим количеством учебных примеров для каждого класса.
Ответ или решение
Переобучение в TFBertForSequenceClassification от Huggingface
Проблема переобучения (overfitting) является распространенной при обучении моделей глубокого обучения, особенно при использовании архитектур, таких как BERT для задач классификации текстов. В вашем случае вы используете TFBertForSequenceClassification для многометочной классификации твитов. При этом, несмотря на хорошую точность на тренировочном наборе, вы наблюдаете низкую точность на валидационном наборе, что указывает на переобучение. Давайте рассмотрим более детально возможные причины и решения этой проблемы.
Причины переобучения
-
Сложность модели: Модель BERT по своей природе очень мощная и имеет множество параметров. Сложность модели может превышать сложность самой задачи, что может привести к тому, что она начинает "запоминать" данные вместо того, чтобы обобщать информацию.
-
Недостаток данных: Если у вас недостаточно учебных примеров для всех классов (в вашем случае 13 классов), модель может не научиться различать их должным образом. Это особенно заметно в контексте многометочной классификации, где для каждого примера могут быть несколько меток.
-
Регуляризация: Хотя вы пытались использовать дроп-аут, его величина может быть не оптимальной, либо другие виды регуляризации могут отсутствовать.
Рекомендации по решению проблемы переобучения
-
Увеличение данных (Data Augmentation): Попробуйте применять методы увеличения данных, такие как синонимизация, изменение порядка слов в предложении или добавление шумов. Эти методы помогут обучить модель на большем количестве уникальных примеров.
-
Углубление архитектуры:
- Попробуйте добавить несколько полносвязных слоев после выходного сигнала BERT. Расширенные модели обычно способны лучше обобщать информацию. Поскольку вы используете 13 классов, добавление 2-3 полносвязных слоев с дроп-аутом между ними может помочь улучшить результаты.
- Используйте подход "Fine-tuning", но с меньшей скоростью обучения на новых слоях.
-
Настройка гиперпараметров:
- Экспериментируйте с различными значениями скорости обучения. Часто более низкая скорость обучения, такая как 2e-5 или даже 1e-5, может улучшить обобщающую способность модели.
- Попробуйте разные значения
epsilonиclipnormоптимизатора, чтобы добиться более стабильной работы.
-
Более эффективное использование дропаута: Досканируйте архитектуру модели для более целенаправленного применения дропаута. Возможно, следует использовать различные значения дропаута на разных уровнях модели.
-
Использование ранней остановки и кросс-валидации: Настройте механизм ранней остановки (
EarlyStopping), чтобы прекратить обучение, когда валидационная точность перестает улучшаться. Используйте кросс-валидацию, чтобы надежно оценить параметры модели.
Заключение
При использовании TFBertForSequenceClassification для многометочной классификации твитов важно учитывать множество факторов, способствующих переобучению. Разработка более глубоких моделей, эффективная регуляризация и умелая работа с данными могут значительно улучшить производительность вашей модели на валидационном наборе. Не забывайте о важности экспериментов: каждый набор данных уникален, и для достижения наилучшего результата потребуется проверка множества стратегий и подходов.