Вопрос или проблема
У меня есть набор данных из 2 классов, каждый из которых содержит 2000 изображений. Я разделил его на 1500 изображений для обучения и 500 изображений для проверки.
Это простая структура для целей тестирования, и каждое изображение классифицируется в зависимости от цвета определенного пикселя. Либо зеленый, либо красный.
Я запускал эту модель много раз и обнаружил, что иногда модели достигают низких значений потерь/высокой точности за несколько эпох, но в другие разы застревают на точности 50%.
Наборы данных каждый раз точно такие же, единственное различие заключается в параметре “shuffle” в model.fit.
Сначала я протестировал диапазон LR:
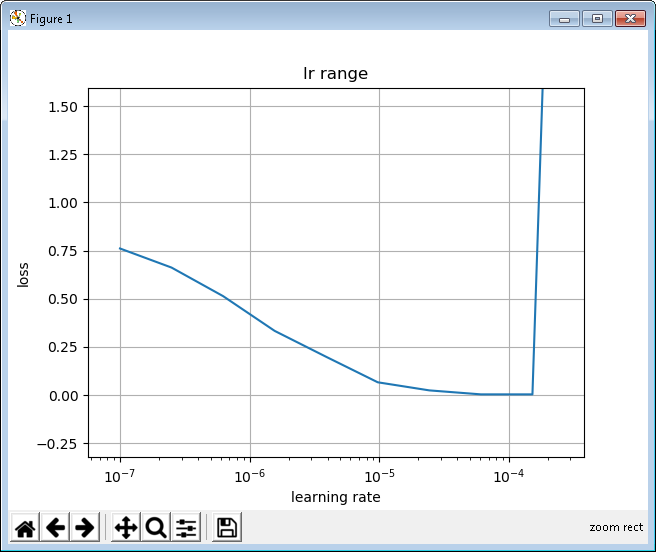
и я “циклирую” скорость обучения через подходящий диапазон.
model = keras.Sequential([
keras.layers.Dense(112, activation=tf.nn.relu, input_shape=(224, 224, 3)),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(3, activation=tf.nn.softmax)
])
LRS = CyclicLR(base_lr=0.000005, max_lr=0.0003, step_size=200.)
model.fit(train_images, train_labels, shuffle=True, epochs=10,
callbacks=[checkpoint,
LRS],
validation_data = (test_images, test_labels)
)
Почему модель иногда НЕ дает хорошее соответствие?
ИЗМЕНЕНИЕ 1
Относительно предложения Серали:
myOpt = keras.optimizers.Adam(lr=0.001,decay=0.01)
model.compile(optimizer=myOpt, loss="categorical_crossentropy", metrics=['accuracy'])
reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.2,verbose=1,patience=5, min_lr=0.00001)
Shuffle = True должен давать лучшие результаты, особенно когда вы запускаете больше эпох. Но мне не ясно, почему существует такая большая разница в точности, когда изменяется shuffle. Одним из вариантов, который вы можете попробовать, является увеличение количества эпох и посмотреть, улучшится ли точность. Для shuffle = False
Установка Shuffle в false позволяет использовать ранее обученные данные. Установка этого параметра в true означает, что вы либо хотите переобучить, либо установить эпоху на значение больше 10. Чтобы научиться, но это увеличивает шансы на запоминание (переобучение)
Вы пробовали без части “CycleLR”? Это, очевидно, хорошая идея, но, насколько я знаю, не является стандартной функцией Keras – требует отдельной реализации. Любая небольшая ошибка в этой реализации может вызвать проблемы.
Ответ или решение
Основная причина, почему модель может не всегда обучаться хорошо на одном и том же наборе данных, заключается в ряде факторов, связанных с параметрами обучения, архитектурой модели и подготовкой данных. Рассмотрим эти аспекты более детально.
Теория
-
Перемешивание данных (Shuffle): Перемешивание входных данных — это важный элемент процесса обучения нейронных сетей. Оно позволяет избежать ситуаций, когда модель обучается на данных в определенном упорядочении, что может привести к плохой обобщающей способности. Когда
shuffle=True, данные случайным образом переупорядочиваются в каждой эпохе, что может помочь в избегании локальных минимумов и улучшении обобщающей способности модели. Однако в некоторых случаях перемешивание может привести к непредсказуемым изменениям в порядке, что в сочетании с другими параметрами обучения может привести к различным уровням производительности. -
Обучение и оптимизация: Изучение процесса оптимизации и метода циклического изменения скорости обучения (Cyclic Learning Rate, CLR) может быть причиной нестабильности в обучении модели. CLR может улучшить качество обучения, помогая избежать локальных минимумов. Однако если реализация CLR сделана с ошибками, это может негативно повлиять на обучение.
-
Архитектура модели: Архитектура модели, описанная в вопросе, содержит некоторые особенности, которые могут затруднять обучение. Например, использование
Denseслоя на входном изображении без предварительного уменьшения размерности может привести к избыточной сложности модели, что затруднит обучение.
Пример
Согласно предоставленному описанию, при использовании shuffle=True модель может демонстрировать хорошую производительность в одном запуске (low loss/high accuracy) и плохую — в другом (accuracy 50%). Вероятно, это связано с тем, что порядок данных влияет на то, каким образом модель обучается на этих данных и в какую конечную точку она приходит.
Применение
-
Оптимизация обучения: Начните с проверки корректности реализации циклического изменения скорости обучения. Даже небольшие ошибки в коде могут привести к значительным изменениям в процессе обучения модели. Попробуйте временно отключить
CycleLRи оцените базовую производительность модели. Это поможет определить, какие улучшения были внесены CLR и какие проблемы могут исходить именно от него. -
Перемешивание данных: Проверьте влияние параметра
shuffleна небольшом наборе экспериментов. Возможно, увеличение числа эпох (до 20 или 30) смягчит разницу, особенно если итоговая общая ошибка уменьшается незначительно. Это позволит модели лучше "заглатить" возможные неблагоприятные эффекты, возникающие из-за порядка данных. -
Аугментация данных и регуляризация: Ради эксперимента добавьте аугментацию данных (например, небольшие повороты, увеличения) и более сложные методы регуляризации, такие как Dropout с различными коэффициентами, что может помочь улучшить обобщение.
-
Диагностика архитектуры модели: Пересмотрите архитектуру модели, чтобы убедиться, что она подходит для классификации изображений указанного размера. Попробуйте использовать сверточные слои до плотных (Dense) для автоматического извлечения признаков изображения.
Таким образом, существует множество факторов, которые могут повлиять на обучаемость модели, и, анализируя их, вы можете выявить причину нестабильности обучения и внести необходимые улучшения.