Вопрос или проблема
У меня есть задача классификации с несколькими классами. Она работает довольно хорошо, но на наименее представленных классах — нет. Действительно, вот распределение:
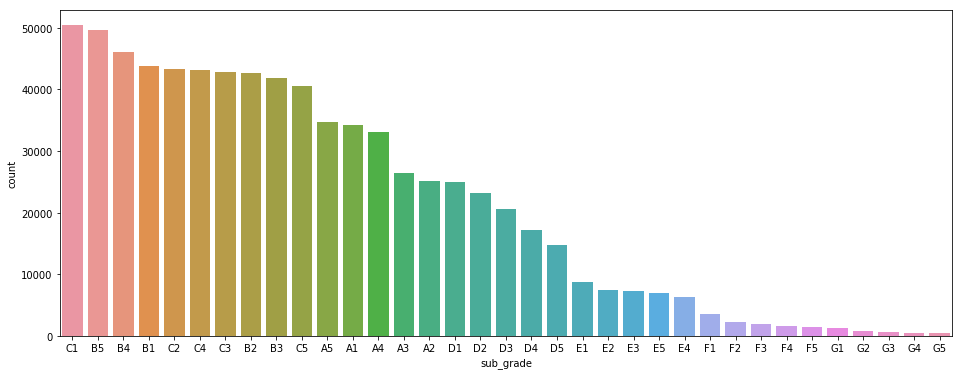
А вот результаты классификации моего предыдущего алгоритма (я убрал цифры с меток):
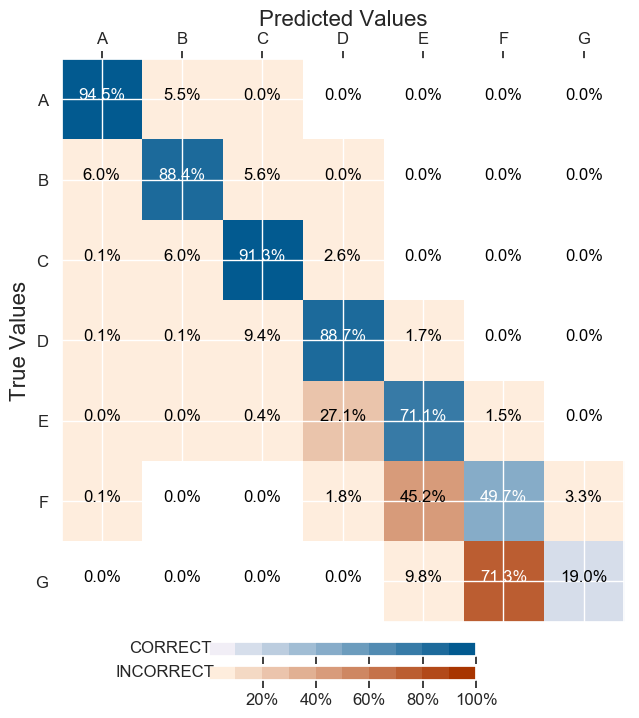 .
.
Поэтому я попытался улучшить классификацию, уменьшив выборку для большинства классов.
import os
from sklearn.utils import resample
# ребалансировка данных
#df = resample_data(df)
if True:
count_class_A, count_class_B, count_class_C, count_class_D, count_class_E, count_class_F, count_class_G = df.grade.value_counts()
count_df = df.shape[0]
class_dict = {"A": count_class_A, "B": count_class_B, "C": count_class_C, "D": count_class_D, "E": count_class_E, "F": count_class_F, "G": count_class_G}
counts = [count_class_A, count_class_B, count_class_C, count_class_D, count_class_E, count_class_F, count_class_G]
median = statistics.median(counts)
for key in class_dict:
if class_dict[key] > median:
print(key)
df[df.grade == key] = df[df.grade == key].sample(int(count_df/7), replace=False)
#replace=False, # без возврата
#n_samples=int(count_df/7), # чтобы соответствовать меньшинству
#random_state=123)
# Разделение набора данных на обучающую и тестовую выборки
x_train, x_test, y_train, y_test = split_data(df, APPLICANT_NUMERIC + CREDIT_NUMERIC,
APPLICANT_CATEGORICAL,
TARGET,
test_size=0.2,
#row_limit=os.environ.get("sample"))
row_limit=552160)
Однако результаты были катастрофическими. Точность модели и потери модели, казалось, имели некоторые проблемы:

И всё было классифицировано как “A” на тестовом наборе.
На вид, метод выборки, который вы использовали, не сработал.
Способ, которым вы используете нарезку и присвоение pandas, немного неверен.
Что-то подобное может сработать:
dfs = []
for key in class_dict:
if class_dict[key] > median:
factor = int(count_df/7)
key_df = df[df.grade == key].sample(factor, replace=False)
else:
key_df = df[df.grade == key]
dfs.append(key_df)
new_train_df = pd.concat(dfs, sort=False)
Хотя это может сработать, есть более прямые способы уменьшения выборки данных (например, установка точного количества ожидаемых образцов из каждого класса).
Этот вопрос также содержит хорошие ответы.
Вы реализуете уменьшение выборки с нуля. В вашей реализации могут быть ошибки.
Другой вариант — использование установленного пакета для уменьшения выборки, такого как under_sampling из imblearn.
.
Ответ или решение
Ваша задача — многоклассовая классификация, где распределение классов не однородно, и вы пытаетесь улучшить производительность модели на менее популярных классах путем даунсемплинга более многочисленных классов. Однако результаты оказались неудачными, и модель начала предсказывать только один класс. Давайте рассмотрим, почему это произошло и как создать более эффективное решение.
Проблема
Основная проблема в данной ситуации заключается в неправильном балансировании данных. Когда вы применяете даунсемплинг, важно сохранить достаточное количество примеров от каждого класса, чтобы модель смогла выучить различия между классами.
Основные причины некорректных предсказаний
-
Неправильная реализация даунсемплинга:
Ваша реализация даунсемплинга создает дисбаланс, что потенциально уменьшает количество примеров для более многочисленных классов слишком сильно. В результате модель теряет эти классы, обучаясь только на той информации, которую получает. -
Отсутствие разнообразия в данных:
Слишком малое количество примеров для определенных классов может привести к тому, что модель не может запомнить их характерные признаки должным образом и начинает предсказывать наиболее многочисленный класс (в данном случае класс "A"). -
Проблемы с параметрами обучения:
При изменении весов классов модель может стать излишне "чувствительной" к одному классу, если не применен правильный подход к балансировке.
Решения
-
Используйте проверенные библиотеки:
Вместо ручной реализации даунсемплинга, настройте его с помощью проверенных инструментов, таких какimblearn. Это поможет избежать ошибок в коде и обеспечить более надежное распределение классов. -
Пересмотрите стратегию даунсемплинга:
Вместо даунсемплинга до медианного значения, оцените использование взвешенных потерь или сбалансированного переподбора (resampling), чтобы добиться равномерного распределения классов. -
Обучение с перераспределением весов:
Воспользуйтесь техникой, где веса классов в функции потерь модели пересчитываются в зависимости от их частоты в обучающем наборе данных. -
Проверка данных на адекватность:
Перед обучением проверьте подготовленные данные на целостность и достаточность для каждого класса, включая распределительное разнообразие значений признаков.
Заключение
Даунсемплинг может быть мощным инструментом, но его неправильная реализация способна существенно ухудшить результаты. Понимание деталей распределения ваших данных и правильное использование инструментов помогут вам избежать ошибок и обеспечить более надежное и эффективное обучение модели. Используйте проверенные методы и подходы для достижения лучших результатов.