Вопрос или проблема
Итак, я пытаюсь использовать модель LSTM для прогнозирования данных температуры на PyTorch. Я относительно новичок как в PyTorch, так и в использовании рекурсивных сетей, поэтому я взял модель, которую нашел в интернете. К сожалению, я работаю с недостающими данными и присваиваю значение 0. Весь проект находится на github, если вам нужны дополнительные сведения.
Из шаблонов я разделил это на два подхода.
Один train2.py принимает кортеж $x=(x_0,…,x_{n-1})$ в качестве входных данных и использует $y=(x_1,…,x_n)$ в качестве целевых значений. Оттуда я рекурсивно вызываю модель $N$ раз, чтобы прогнозировать $N$ раз в будущее. Вот часть кода, которая важна:
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=5, output_size=1):
super().__init__()
self.input_size = input_size
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.lstm2 = nn.LSTM(hidden_layer_size, input_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size).double(),
torch.zeros(1,1,self.hidden_layer_size).double())
self.hidden_cell_2 = (torch.zeros(1,1,self.input_size).double(),
torch.zeros(1,1,self.input_size).double())
def forward(self, input_seq):
inpt = input_seq.view(len(input_seq) ,1, -1).double()
lstm_out, self.hidden_cell = self.lstm(inpt, self.hidden_cell)
lstm_out2, self.hidden_cell_2 = self.lstm2(lstm_out,self.hidden_cell_2)
predictions = lstm_out2.view(len(input_seq), -1)
return predictions.view(-1)
Вот как выглядит вывод (predict2.html)
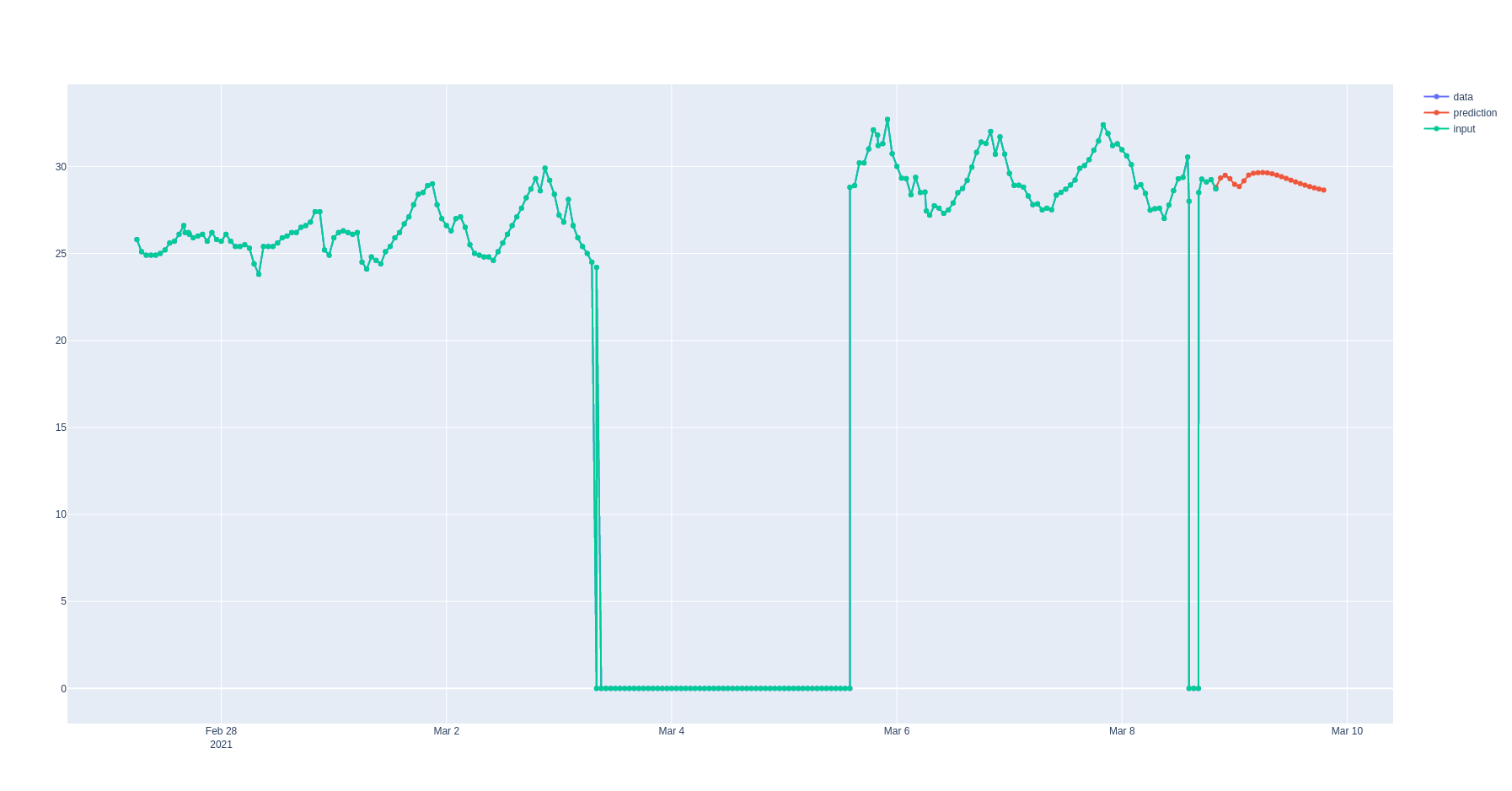
Он в какой-то степени показывает колебания, но амплитуда совершенно неверная.
Второй подход train.py принимает кортеж $x=(x_0,…,x_{\frac{n}{2}-1})$ в качестве входных данных и $y=(x_{\frac{n}{2}},…,x_n)$ в качестве выходных данных. Для прогнозирования в этом случае я делаю единственный вызов к модели и могу рассматривать только $N<\frac{n}{2}$ точек в будущее. Вот код:
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=5, output_size=1, window=10):
super().__init__()
self.window = window
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size).double(),
torch.zeros(1,1,self.hidden_layer_size).double())
self.sigmoid = nn.Sigmoid()
def forward(self, input_seq):
inpt = input_seq.view(len(input_seq) ,1, -1).double()
lstm_out, self.hidden_cell = self.lstm(inpt, self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return self.sigmoid(predictions[-self.window:].view(-1))
Вывод выглядит так:
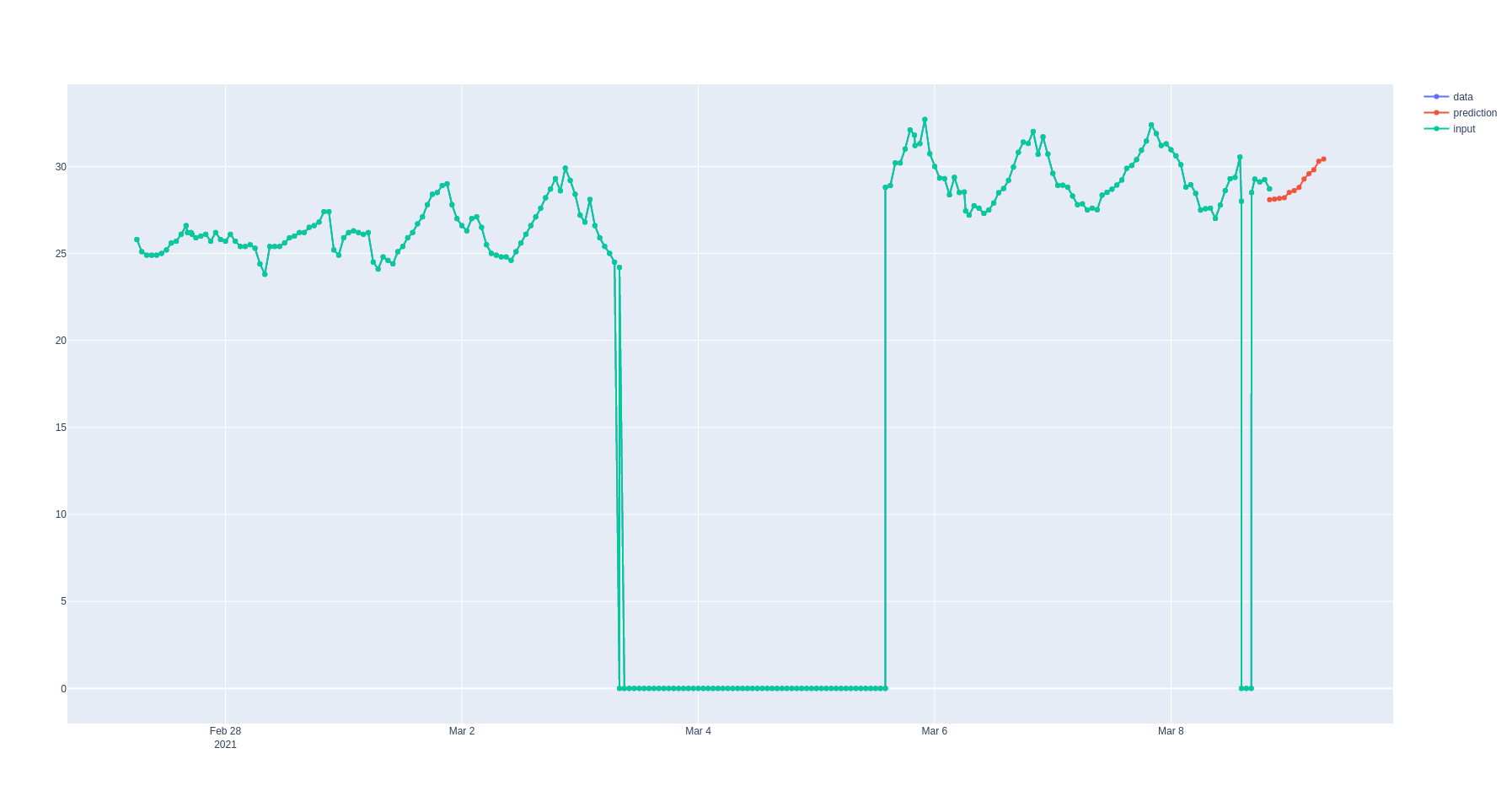
Большую часть времени он не сохраняет непрерывность, вероятно, из-за того, что не имеет стартовой точки для отсчета в выходных данных?
С учетом всего этого мой вопрос: как улучшить прогноз? Должен ли я добавить больше данных? Не использую ли я слишком много скрытых слоев? Не слишком ли сглаживает сигмоида колебания в данных? Является ли модель совершенно неправильной? Мне нужно руководство.
Спасибо за ваше время.
Я думаю, что смог это исправить. Я заменил присвоенное значение nan на 25 вместо 0 (что приблизительно соответствует среднему) и нормализовал значения в интервале (-1,1) с помощью масштабированной сигмоида, смещенной на 25.
Вот как это выглядит сейчас:
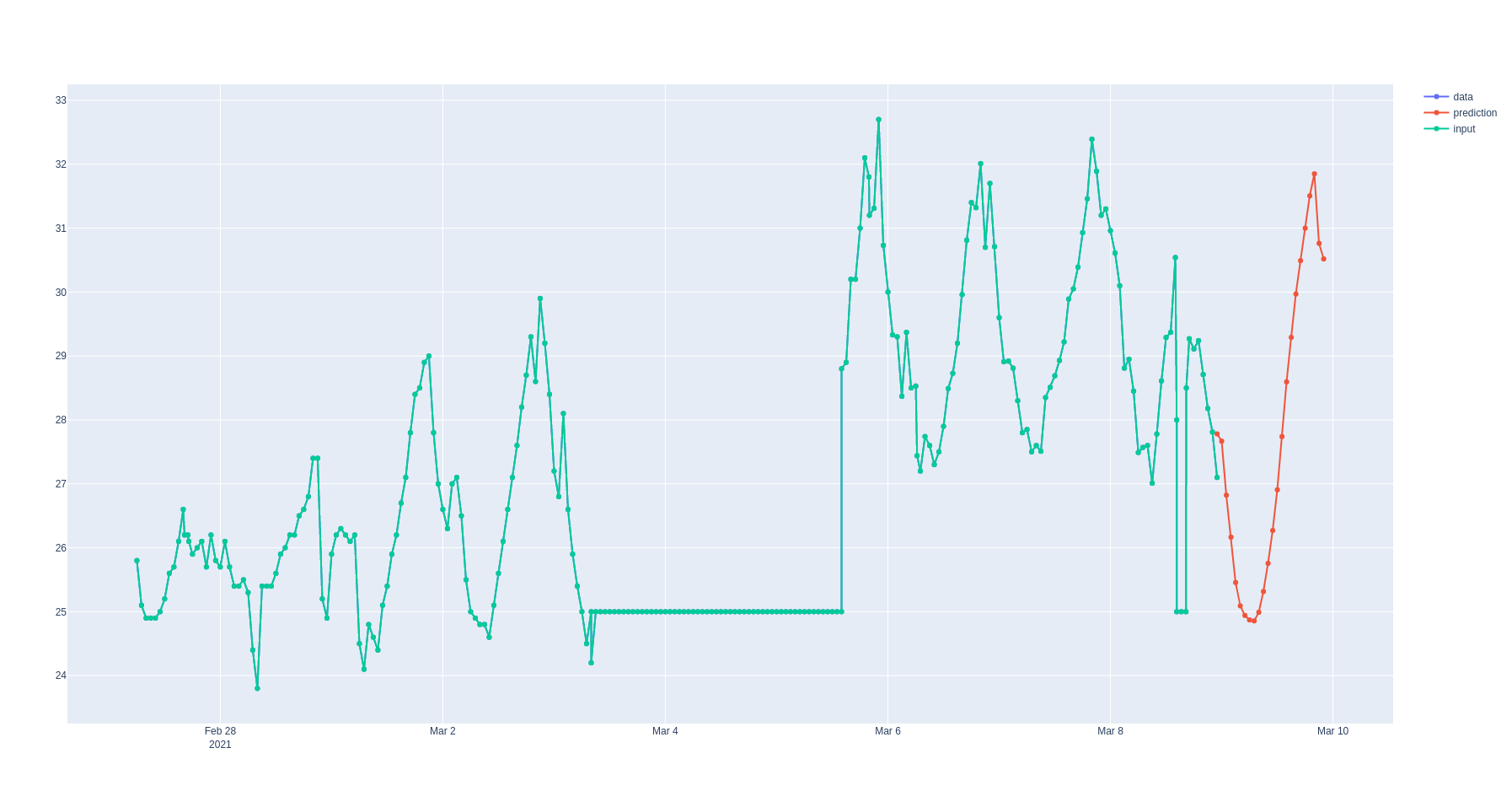
Ответ или решение
Улучшение прогноза временных рядов с помощью LSTM на PyTorch
Ваша задача по прогнозированию температурных данных с использованием LSTM-моделей на PyTorch является интересной и актуальной. Давайте детально рассмотрим, как можно улучшить результаты вашей модели и достичь более точных прогнозов.
1. Обработка пропусков в данных
Вы упомянули, что пропуски в данных изначально заполнялись нулями. Это могло негативно сказаться на качестве модели, так как такие преобразования вводят искусственные данные, которые могут не отражать реальное состояние дел. Как вы уже заметили, замена нуля на 25 (среднее значение) и нормализация значений в интервале (-1, 1) с использованием сдвинутого сигмоида – это шаг в правильном направлении. Однако, есть и другие подходы:
- Интерполяция: Рассмотрите возможность линейной или полиномиальной интерполяции недостающих значений. Это может значительно улучшить качество данных.
- Методы заполнения: Использование методов, таких как K-ближайших соседей или временных рядов, для заполнения пропусков может быть более эффективным.
2. Архитектура вашей LSTM-модели
Анализируя архитектуры, вы используете два подхода с разными архитектурами LSTM. Вот несколько советов по оптимизации:
- Количество скрытых слоев: Слишком много скрытых слоев может усложнить модель и привести к переобучению. Попробуйте уменьшить количество LSTM-слоев до одного или двух и проанализируйте результаты.
- Размер скрытого слоя: Попробуйте изменять размер скрытого слоя. Например, увеличение размера до 50 или 100 может помочь вам улавливать более сложные зависимости в данных.
- Недостаточная обучающая выборка: Увеличьте объем обучающей выборки, если это возможно. Больше данных позволит модели лучше обобщать.
3. Техника предсказания
Постарайтесь экспериментировать с способами, которыми вы выполняете предсказания:
- Итеративное предсказание: В вашем первом подходе вы делаете многократные предсказания, используя выход предыдущего шага как новый вход. Убедитесь, что модель хорошо обобщает на нескольких предсказаниях. Возможно, стоит уменьшить количество предсказаний.
- Прямое предсказание: Во втором методе, где вы делаете одно предсказание за один шаг, вероятно, стоит больше экспериментировать с входными данными и их размерностью. Возможно, вам следует использовать большее количество предыдущих шагов, чем n/2.
4. Параметры обучения
Параметры обучения, такие как размер батча и скорость обучения, играют важную роль в процессе оптимизации. Убедитесь, что вы используете подходящие значения:
- Размер батча: Поиграйте с размером батча. Иногда даже увеличение размеров батча может помочь в улучшении стабильности и производительности модели.
- Скорость обучения: Ошибки могут возникать из-за слишком большой или слишком малой скорости обучения. Оптимизация этого параметра может существенно улучшить качество предсказаний.
5. Использование дополнительных методов
Не забывайте о возможности применения различных методов и технологий для улучшения вашего проекта:
- Регуляризация: Добавление Dropout или L2-регуляризации может помочь предотвратить переобучение.
- Аугментация данных: Создание дополнительных временных рядов с использованием небольших шумов или сдвигов во времени может обогатить тренировочные данные.
- Совмещение моделей: Рассмотрите возможность использования ансамблей моделей для получения более надежных прогнозов.
Заключение
Улучшение прогнозирования временных рядов с использованием LSTM — это итеративный процесс, который требует тщательной настройки модели и тщательного анализа данных. Применяя вышеуказанные стратегии, вы сможете достичь лучших результатов и повысить точность прогноза. Они не только помогут вам добиться более высоких показателей, но и обогатят ваш опыт работы с LSTM и PyTorch. Удачи вам в ваших исследованиях!