Вопрос или проблема
Я хочу создать точечный/линейный график с рядов для каждого пациента, используя пары x/y, полученные из данных столбца этого пациента. Небольшой образец данных выглядит следующим образом:
ID пациента 1 2
Контрольный_Процент_1 0.000 0.000
Контрольный_Процент_2 0.035 0.000
Контрольный_Процент_3 0.035 0.039
Контрольный_Процент_4 0.053 0.053
Контрольный_Процент_5 0.088 0.066
Контрольный_Процент_6 0.088 0.066
Контрольный_Процент_7 0.105 0.092
Контрольный_Процент_8 0.123 0.171
Контрольный_Процент_9 0.158 0.263
Контрольный_Процент_10 0.158 0.224
Контрольный_Процент_11 0.197
Контрольный_Процент_12 0.211
Контрольный_Процент_13 0.276
Контрольный_Процент_14
Контрольный_Процент_15
Контрольный_Процент_16
Контрольный_Процент_17
Контрольные_Дни_1 33 32
Контрольные_Дни_2 378 128
Контрольные_Дни_3 575 502
Контрольные_Дни_4 951 633
Контрольные_Дни_5 1127 800
Контрольные_Дни_6 1324 853
Контрольные_Дни_7 1512 999
Контрольные_Дни_8 1887 1122
Контрольные_Дни_9 2141 1312
Контрольные_Дни_10 2331 1467
Контрольные_Дни_11 1657
Контрольные_Дни_12 2022
Контрольные_Дни_13 2393
Контрольные_Дни_14
Контрольные_Дни_15
Контрольные_Дни_16
Каждая пара “Контрольный_Процент” соответствует “Контрольным_Дням”, описывающим результат y после x дней после операции. Это легко сделать в Excel, определяя каждую серию x и y вручную на точечном графике.
Как это можно сделать в R или ggplot2?
Я понимаю, что вы хотите, чтобы Дни были по оси x, а Процент по оси y с отдельной линией для каждого пациента. Вот один из способов сделать это. Я сохранил промежуточные результаты, чтобы лучше понять процесс обработки данных.
library(tidyverse)
DF <- read_csv("~/R/Play/Dummy.csv")
#> Предупреждение: Одно или несколько проблем с парсингом, вызовите `problems()` для вашего фрейма данных для получения деталей,
#> например.:
#> dat <- vroom(...)
#> проблемы(dat)
#> Строки: 32 Столбцы: 3
#> ── Спецификация столбца ────────────────────────────────────────────────────────
#> Разделитель: ","
#> chr (1): Patient_ID
#> dbl (2): 1, 2
#>
#> ℹ Используйте `spec()`, чтобы получить полную спецификацию столбца для этих данных.
#> ℹ Укажите типы столбцов или установите `show_col_types = FALSE`, чтобы отключить это сообщение.
DF2 <- DF |> rename("P1" = `1`, "P2" = `2`) |> filter(!is.na(P1) | !is.na(P2))
DF3 <- DF2 |> pivot_longer(cols = c("P1","P2"),names_to = "Пациент")
DF4 <- DF3 |> separate("Patient_ID", into = c("Контроль", "Измерение", "Индекс"))
DF5 <- DF4 |> pivot_wider(names_from = "Измерение", values_from = "value" )
DF5
#> # Тиббл: 26 × 5
#> Контроль Индекс Пациент Процент Дни
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Контроль 1 P1 0 33
#> 2 Контроль 1 P2 0 32
#> 3 Контроль 2 P1 0.035 378
#> 4 Контроль 2 P2 0 128
#> 5 Контроль 3 P1 0.035 575
#> 6 Контроль 3 P2 0.039 502
#> 7 Контроль 4 P1 0.053 951
#> 8 Контроль 4 P2 0.053 633
#> 9 Контроль 5 P1 0.088 1127
#> 10 Контроль 5 P2 0.066 800
#> # ℹ еще 16 строк
ggplot(DF5, aes(x = Дни, y = Процент, color = Пациент, group = Пациент)) +
geom_line() +geom_point()
#> Предупреждение: Удалено 3 строки с отсутствующими значениями или значениями вне диапазона
#> (`geom_line()`).
#> Предупреждение: Удалено 3 строки с отсутствующими значениями или значениями вне диапазона
#> (`geom_point()`).
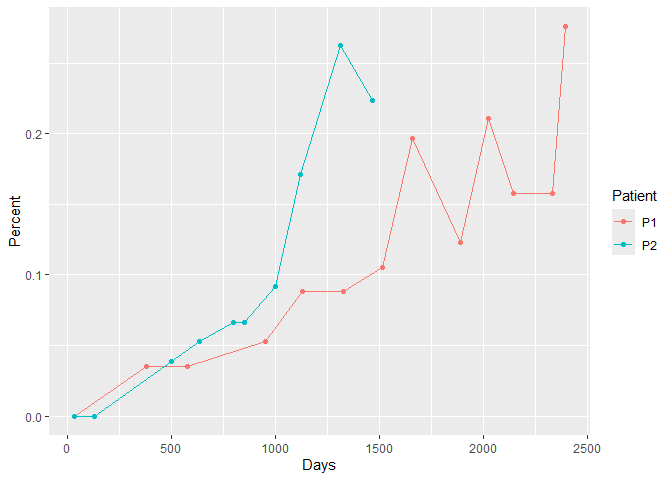
Создано 2024-10-26 с reprex v2.1.1
Ответ или решение
Построение графиков с x и y значениями в одном столбце с использованием ggplot2 в R
Введение
Если вы хотите построить график, который отображает поведение нескольких пациентов с использованием значений, находящихся в одном столбце, в R существует мощный пакет визуализации данных — ggplot2. В данном руководстве подробно рассмотрим, как преобразовать ваши данные и построить график, используя примеры с фокусом на Patient ID, Controll_Percent и Controll_Days.
Исходные данные
Ваша таблица выглядит примерно так:
| Patient ID | 1 | 2 |
|---|---|---|
| Controll_Percent_1 | 0.000 | 0.000 |
| Controll_Days_1 | 33 | 32 |
| … | … | … |
Каждая "Controll_Percent" соответствует определенному количеству "Controll_Days". Для визуализации зависимости процента (y) от дней (x) для каждого пациента, необходимо будет сначала правильно отформатировать данные.
Шаги по подготовке данных
-
Импорт данных и базовая подготовка:
Убедитесь, что у вас установлен пакетtidyverse, который содержитggplot2и другие полезные инструменты для работы с данными.library(tidyverse) # Загрузка данных DF <- read_csv("~/R/Play/Dummy.csv") -
Ренеймы и фильтрация:
Переименуйте ваши столбцы для удобства, а затем уберите NA-значения.DF2 <- DF %>% rename("P1" = `1`, "P2" = `2`) %>% filter(!is.na(P1) | !is.na(P2)) -
Преобразование данных:
Используйте функциюpivot_longerдля преобразования таблицы из широкого в длинный формат, что упростит анализ.DF3 <- DF2 %>% pivot_longer(cols = c("P1", "P2"), names_to = "Patient") -
Отделение компонентов:
РазделитеPatient_IDна отдельные компоненты, чтобы получить более четкую структуру данных.DF4 <- DF3 %>% separate("Patient_ID", into = c("Control", "Measure", "Index")) -
Финальное преобразование:
С помощьюpivot_widerверните данные в нужный вид.DF5 <- DF4 %>% pivot_wider(names_from = "Measure", values_from = value)
Построение графика
Теперь, когда ваши данные обработаны, можно добавлять графики:
ggplot(DF5, aes(x = Days, y = Percent, color = Patient, group = Patient)) +
geom_line() +
geom_point() +
labs(title = "Зависимость процента от дней для разных пациентов",
x = "Число дней",
y = "Процент контроля") +
theme_minimal()Заключение
Данный подход позволяет эффективно визуализировать зависимости между разными переменными в одном графике. Используя пакеты tidyverse и ggplot2, вы сможете быстро преобразовать любые наброски данных в полноценные визуализации. Не забудьте проверить на наличие NA-значений в ваших данных, так как они могут повлиять на результат графика.
Дополнительные материалы
- Документация пакета ggplot2
- Туториалы по R и Tidyverse
- Интерактивные графики с использованием plotly
Теперь вы готовы создавать свои собственные графики, используя ggplot2!