Вопрос или проблема
Я предполагаю, что изображение стоит многих слов, поэтому вот изображение:
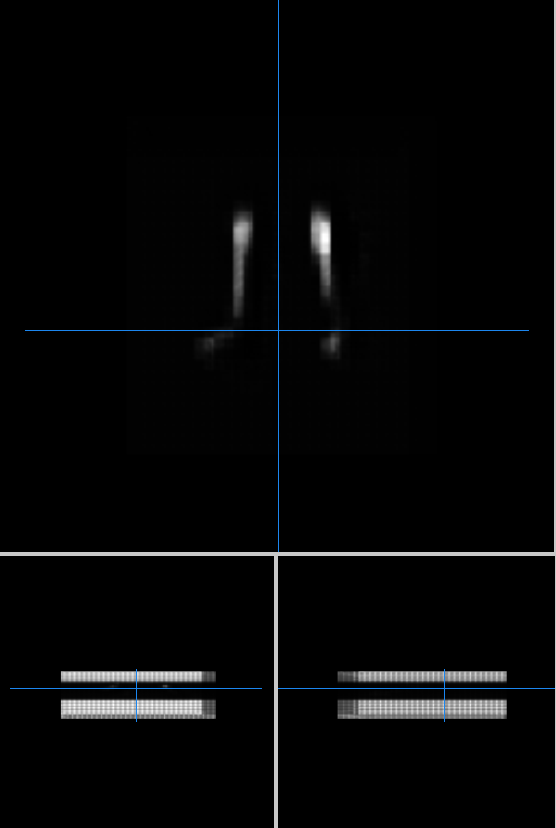

Как вы можете видеть, в середине, где необходимо сегментировать воксели, артефактов нет. В то время как сверху и снизу я получаю красивый артефакт в виде шахматной доски. Это предсказание. Модель была обучена на трех 3D изображениях, а валидационный набор состоял из тех же трех изображений. Это обучение было тестом на переобучение. Оно хорошо переобучается, но артефакты сверху и снизу присутствуют. Срезы сверху и снизу с артефактами не имеют сегментированных пикселей, что заставляет меня думать, что нейронная сеть выдает фальшивые данные для срезов, где нечего выдавать. Я просто не понимаю, почему и как от этого избавиться. Есть идеи?
Правка: Я думаю, что это связано меньше с артефактом шахматной доски, чем с тем, что нейронная сеть вставляет данные в срезы, которые не имеют информации, т.е. воксели в срезах сверху и снизу все нули (0). Я избавился от узора шахматной доски с помощью этого метода: https://arxiv.org/pdf/2002.02117.pdf (Суть: добавьте фиксированный сверткивающий слой сразу после обратной свертки). Изменение уменьшило узор шахматной доски, но я все еще получаю заполненные верхние и нижние части:

Я нашел решение.
Для того чтобы обучить модель и сегментировать поражения, метка должна содержать два класса: (1) каждый воксель, который обозначает поражение, и (2) каждый воксель, который не является поражением. Метка изображения содержала только воксели с поражениями. Чтобы получить два класса, я использовал tensorflow.keras.utils.to_categorical. Модель обучается вполне нормально, и выход — это softmax, дающий значения от 0 до 1.
Выход показывает сегментацию без возврата к двум категориям. Каждый срез отображается индивидуально, а интенсивность масштабируется в соответствии с его максимальным значением. Срезы с артефактами имеют очень низкие значения (например, 0.000001834), в то время как те, что без артефактов (те, что ближе к центру) имеют гораздо более высокие значения (например, 0.3421). Таким образом, артефакты с очень низкой интенсивностью показываются как самые высокие значения.
Решение заключается в возврате от tensorflow.keras.utils.to_categorical. Нам нужно получить все релевантные воксели, которые имеют очень высокие значения и преобразовать их в единицы, в то время как несущественные воксели (т.е. артефакты) должны быть преобразованы в нули.
Вот как это сделать:
predicted = np.argmax(model.predict(data_to_predict), axis=-1)
Функция numpy argmax() возвращает индексы максимальных значений вдоль оси. Мы возвращаем их вдоль последней оси, которая является осью двух каналов (нет поражения, поражение).
Ответ или решение
Вопрос о наличии артефактов «шахматной доски» в сегментации 3D U-Net покрывает несколько аспектов, связанных с обработкой медицинских изображений, обучением нейронных сетей и корректной интерпретацией выходных данных моделей. Давайте рассмотрим основные детали и предложим решение проблемы.
Проблема артефактов в сегментации
На основании вашего описания, артефакты проявляются на верхних и нижних срезах 3D-изображения, где отсутствуют сегментированные воксели. Указание на отсутствие информации на краевых срезах говорит о возможности того, что нейронная сеть «восстанавливает» данные, основываясь на имеющихся данных, что и приводит к искажению в виде шахматных паттернов или фальшивой информации.
Причины возникновения артефактов
-
Недостаточная информация для обучения: Обучение нейронной сети на ограниченном наборе изображений может привести к переобучению модели, особенно если нет разнообразия в обучающих данных. В данном случае модель может не учитывать нереальные или потерянные данные на краях изображений, что и приводит к нежелательным артефактам.
-
Классификация без второго класса: Вы правильно заметили, что для корректной классификации необходимо иметь два класса: воксели с поражениями и воксели без поражений. Если ваша метка содержит только воксели с поражением, модель не получает необходимой информации о том, как выглядят «негативные» воксели, что может привести к некорректной интерпретации пустых областей как содержащих нежелательную информацию.
Решение проблемы
Ваше решение, а именно внедрение второго класса при помощи функции to_categorical, позволяет сети лучше понимать границы между классами. При этом необходимо корректно обрабатывать выходные данные модели, чтобы устранить артефакты и достичь более точных результатов:
-
Использование функции
argmax: Применение функцииnp.argmax(model.predict(data_to_predict), axis=-1)позволяет извлекать наиболее вероятный класс из выходного слоя нейронной сети. Это оптимальный подход для превращения вероятностных выходных данных в четкие классы, что позволяет исключить ложные положительные результаты, проявляющиеся в виде артефактов. -
Постобработка предсказаний: Возможно также применение порогового значения (thresholding) на результатах предсказания, чтобы игнорировать значения с низкой вероятностью, которые могут быть причиной появления артефактов. Например, если вероятность для какого-либо воксела ниже 0.01, его стоит интерпретировать как ‘негатив’ (нулевой класс).
-
Увеличение обучающего набора: Если есть возможность, получите больше данных для обучения. Использование методов увеличения данных (data augmentation) поможет в получении большего разнообразия в обучающих данных и улучшит общую эффективность модели.
-
Использование метода зависящего от контекста: Возможно, стоит рассмотреть архитектуры, которые учитывают контекст (например, дополнительные свертки или объединяющие слои), что может помочь в корректной интерпретации краевых данных.
В заключение, решение проблемы артефактов в сегментации 3D U-Net требует комплексного подхода, включающего как корректировку структуры обучения, так и предобработку выходных данных. Ваша находка о необходимости двух классов при сегментации ключевая, и правильная обработка выходных данных сможет значительно улучшить качество сегментации и снизить влияние артефактов.