Вопрос или проблема
У меня есть тысячи заголовков, и я хотел бы построить семантическую сеть с использованием word2vec, в частности файлов Google News. Мои предложения выглядят так:
Заголовки
Собаки — лучшие друзья людей
Собака погибла из-за несчастного случая
Вы можете очистить лапы собак, используя натуральные продукты.
Кошка была найдена на кухне
И так далее.
Я хотел бы найти какой-то специфический шаблон в этих данных, например, сходство в темах о собаках и кошках, используя семантические сети. Можете ли вы дать мне совет, как это сделать?
Код:
import pandas as pd
import gensim
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from sklearn.manifold import TSNE
main_data.Titles = np.where(main_data.Titles.isnull(),'NA', main_data.Titles)
article_titles = main_data['Titles']
titles_list = [title for title in article_titles]
big_title_string = ' '.join(titles_list)
tokens = word_tokenize(big_title_string)
words = [word.lower() for word in tokens if word.isalpha()]
stop_words = set(stopwords.words('english'))
words = [word for word in words if not a word in stop_words]
model = gensim.models.KeyedVectors.load_word2vec_format('path/GoogleNews-vectors-negative300.bin', binary = True)
model.vector_size
vector_list = [model[word] for word in words if word in model.vocab]
words_filtered = [word for word in words if the word in `model.vocab`]
word_vec_zip = zip(words_filtered, vector_list)
word_vec_dict = dict(word_vec_zip)
df = pd.DataFrame.from_dict(word_vec_dict, orient="index")
tsne = TSNE(n_components = 2, init="random", random_state = 10, perplexity = 100)
tsne_df = tsne.fit_transform(df[:400])
sns.set()
fig, ax = plt.subplots(figsize = (11.7, 8.27))
sns.scatterplot(tsne_df[:, 0], tsne_df[:, 1], alpha = 0.5)
from adjustText import adjust_text
texts = []
words_to_plot = list(np.arange(0, 400, 10))
for word in words_to_plot:
texts.append(plt.text(tsne_df[word, 0], tsne_df[word, 1], df.index[word], fontsize = 14))
adjust_text(texts, force_points = 0.4, force_text = 0.4,
expand_points = (2,1), expand_text = (1,2),
arrowprops = dict(arrowstyle = "-", color="black", lw = 0.5))
plt.show()
Однако я не могу понять, как интерпретировать результаты. Думаю, они неверные, и этот подход, вероятно, не подходит для построения семантической сети. Возможно, я что-то упустил… Например, этот код все еще сохраняет стоп-слова после части
words = [word for word in words if not a word in stop_words]
Это пример вывода, который трудно прочитать и объяснить (по крайней мере, для меня):
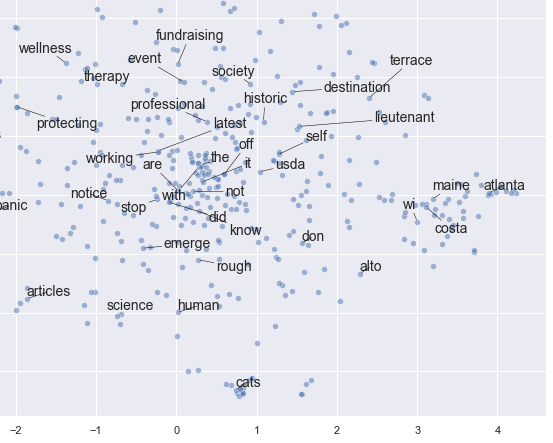
Я был бы очень признателен, если бы вы могли дать мне несколько советов и рекомендаций по созданию семантической сети, которая может показать семантическое сходство внутри заголовков.
Вы можете попробовать преобразовать представление слов в представление документа, просто взяв среднее по векторам слов для документа. Например, если в документе 9 слов с размерностью (9, 200), то взяв среднее по словам, вы сможете получить представление документа с размерностью (1,200).
После того как у вас будет представление документа, вы можете использовать T-SNE для нахождения похожих документов. Документы с похожей темой или тематикой будут сгруппированы рядом друг с другом. Вы всегда можете улучшить представление документа, улучшив векторы слов.
Проверьте это
.
Ответ или решение
Создание семантической сети на основе модели word2vec — это интересный и полезный подход для анализа текстовых данных с целью выявления скрытых закономерностей и объединений по темам в коллекции заголовков. Построение таких сетей позволяет понять, какие темы присутствуют и как слова взаимосвязаны между собой в контексте крупных текстовых массивов. Рассмотрим теоретические аспекты, пример реализации и применение этой методики на практике.
Теория
Word2vec — это инструмент, который преобразует каждое слово в числовой вектор высокой размерности, отражая семантическое положение слов. Замысел векторного представления слов заключается в том, что слова, близкие по смыслу, будут иметь схожие векторы. Модель word2vec обучается на большом корпусе текстов, чтобы захватить контекстное значение слов. Самым популярным набором предварительно обученных векторов является модель, обученная на корпусе Google News.
После преобразования слов в векторы, мы можем осуществить анализ семантических связей между ними. Это достигается благодаря тому, что векторные представления позволяют использовать линейную алгебру для оценки подобия между словами. Например, вектора для слов, связанных с собаками, должны быть ближе друг к другу в многомерном пространстве, чем слова, не имеющие отношение к собакам.
Пример
В вашем коде используется python-библиотека Gensim для загрузки модели word2vec и получения векторов для слов в заголовках. Основные шаги выполняются следующим образом:
-
Предобработка текста: Текстовые данные должны быть очищены от стоп-слов и приведены к нижнему регистру. В коде предобработка выполнена с использованием NLTK. Обратите внимание, что в строке
words = [word for word in words if not a word in stop_words]есть синтаксическая ошибка — нужно заменитьa wordнаword. -
Создание векторов: Для каждого слова, присутствующего в модели google news, формируется вектор. Слово отбрасывается в случае отсутствия в модели.
-
Визуализация: Для визуализации многомерных данных используется метод t-SNE, который позволяет отображать высокоразмерные данные на двухмерной площади с сохранением относительных расстояний между векторами.
Применение
Для практического применения модели word2vec и t-SNE к вашей задаче:
-
Документные векторы: Примените среднее взвешивание векторов на уровне документов. Это означает, что для каждого заголовка вы можете усреднить векторы всех содержащихся в нем слов, получая вектор для всего заголовка.
-
Анализ тематических объединений: Исследуйте полученные двумерные представления (после применения t-SNE) для выявления тематических кластеров. Например, вы можете обнаружить, что группы заголовков, упоминающие “собак”, находятся близко друг к другу, в то время как заголовки про “кошек” образуют другой кластер.
-
Улучшение результата: Работайте с улучшением модели векторов, обогащением набора данных, настройкой гиперпараметров t-SNE (таких как перплексия и число итераций) для получения более четких и осмысленных кластеров.
При интерпретации результатов обратите внимание на то, как близко расположены ключевые слова в визуализированном пространстве. Это даст представление о темах и концепциях, скрытых в ваших данных. Сохранение процесса итеративным поможет вам дополнительно уточнить и улучшить семантическую сеть, делая ее более корректной и полезной для анализа.