Вопрос или проблема
Я ищу программное обеспечение для добавления семантических тегов к длинному структурированному тексту с возможностью их поиска, извлечения и, возможно, анализа.
В частности, текст структурирован по главам и подглавам. Внутри них содержатся описания конкретных требований и руководств по реализации. Структура глав важна, и она должна быть доступна во всех извлечениях/анализе (например, мне нужно знать, в какой главе находится тег).
Я хочу помечать эти требования, руководства и т.д. и иметь возможность их извлекать, например, “покажите мне все требования типа X”.
Я хотел бы иметь это в виде автономного программного обеспечения, которое можно установить на ноутбуки консультантов. Ноутбуки все работают на Windows, но если оно также будет работать на OS X, это значительно упростит разработку.
Моя конечная цель — сопоставить требования с конкретной установкой в виде контрольного списка/аудита. Если инструмент может делать что-то подобное, было бы великолепно. Если нет, мне будет достаточно извлечения данных и создания контрольного списка отдельно. Я хотел бы иметь возможность связываться с полным текстом при составлении контрольного списка, на случай, если возникнут более детализированные вопросы (“хорошо, мы соответствуем? Что именно там сказано?”).
Я думаю, что смогу построить что-то подобное в SMW, семантическом ПО, которое я знаю лучше всего, но я бы предпочел автономное решение, которое не требует локального веб-сервера. Таким образом, автономное ПО, похожее на SMW, также может удовлетворить мои потребности.
Вы должны иметь возможность создать что-то подобное с использованием python и набора инструментов для обработки естественного языка – nltk Auto-tagify может быть хорошей отправной точкой.
Python и NLTK являются бесплатными, открытыми программами, которые можно использовать коммерчески и которые работают на различных платформах. Если вы решите использовать веб-сервер, Python может запустить легковесный сервер с одной командной строкой или имеет множество фреймворков, также доступны различные GUI-фреймворки.
Ну, я считаю, что вам нужен XML-редактор (как менеджер баз данных). Вот что я нашел: Oxygen XML Editor

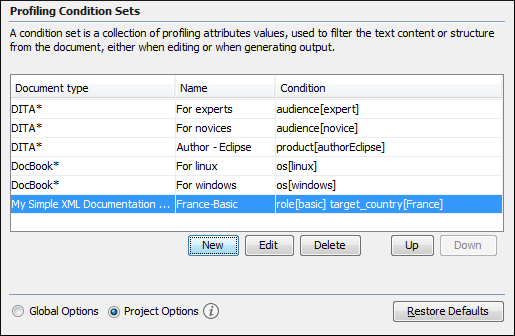
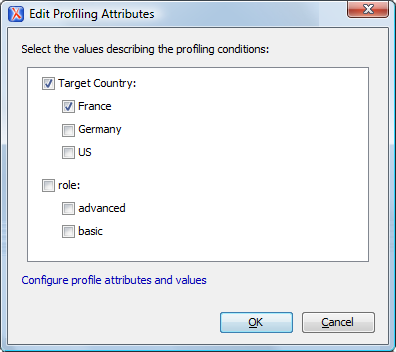
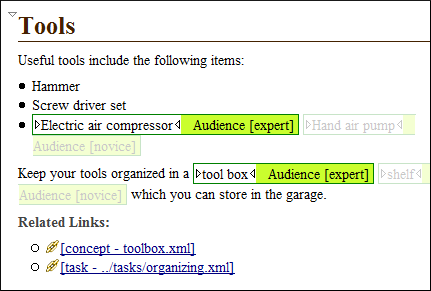
ИСПРАВЛЕНИЕ: Конечно, вам нужно делать структуру по одной. Я не знаю, можно ли это автоматизировать, если у вас слишком длинный текст.
Вы можете поискать xml редактор или список xml редакторов для альтернатив.
Ответ или решение
Семантическое тегирование и анализ/извлечение текста для Windows и OS X
В современном мире, где объемы информации увеличиваются с каждым днем, необходимость в инструментах для семантического тегирования и анализа текста становится все более актуальной. В вашем запросе вы четко описали требования к программному обеспечению, которое должно поддерживать структурированный текст, содержащий главы и подвалы, и обеспечивать возможность поиска, извлечения и анализа данных по заданным тегам. Ниже представлен обзор доступных решений, которые могут удовлетворить ваши потребности, а также примеры использования технологий, таких как Python и NLTK.
Целевые функции программного обеспечения
- Семантическое тегирование: Возможность добавления меток к требованиям и руководствам, чтобы эти данные можно было легко извлекать.
- Структурированное извлечение: Необходимость извлечения информации с учетом структуры текста (глава, подглава и т.д.), что особенно важно для обеспечения точности и контекста.
- Анализ данных: Инструменты, которые позволят производить анализ меток и соответствие требованиям для последующих проверок или аудитов.
- Удобный интерфейс: Пользовательский интерфейс должен быть доступным и интуитивно понятным для консультантов.
- Кроссплатформенность: Программное обеспечение должно функционировать как на Windows, так и на OS X.
Рекомендуемые решения
-
Oxygen XML Editor:
- Это мощный инструмент для работы с XML, который предлагает функции семантического тегирования и встроенные инструменты для анализа и визуализации. С помощью Oxygen XML Editor вы сможете формировать документ с поддержкой меток и структур, что позволит вам легко извлекать данные по заданным критериям.
- Данный редактор позволяет удобно работать с большими объемами информации и поддерживает использование различных схем, что делает его отличным выбором для вашей задачи.
-
Python и библиотека NLTK:
- Если вы рассматриваете вариант разработки собственного инструмента, языки Python и NLTK предоставляют гибкость для создания мощного решения. В частности, вы можете использовать библиотеку для автоматического тегирования и последующего анализа текста.
- Auto-tagify – это библиотека, которая может помочь в создании системы семантического тегирования. Вы сможете адаптировать её под свои нужды и добавить дополнительные функции, такие как извлечение данных по тегам и структурирование информации.
-
Программное обеспечение для управления данными:
- Рассмотрите возможность использования специализированных решений, таких как Notion или Evernote, которые, хотя и не являются строго семантическими инструментами, позволяют наличием тегов и структур, которые могут быть упрощены для ваших нужд.
Рекомендации по реализации
- Определите структуру данных: Прежде чем приступить к выбору программного обеспечения, убедитесь, что у вас четкое представление о структуре документа, включая главы, подглавы и категории требований.
- Тестирование различных решений: Рекомендуется протестировать несколько вариантов, чтобы определить, какое из программных обеспечений наиболее удобно для работы вашей команды.
- Обучение и документация: Не забывайте о важности обучения ваших сотрудников использованию выбранного инструмента. Поставьте перед собой цели по обучению и созданию документации для облегчения адаптации.
Заключение
Ваш запрос о семантическом тегировании и извлечении данных из структурированного текста требует применения современных инструментов для управления информацией. Выбор между сторонним программным обеспечением, таким как Oxygen XML Editor, и разработкой собственного решения с использованием Python и NLTK зависит от ваших конкретных нужд и ресурсов. Продолжайте исследовать возможности и выбирайте инструмент, который максимально оправдает ваши ожидания.