Вопрос или проблема
У меня есть прикрепленный документ. Я импортировал документ xlxs в R. Я хотел бы избавиться от всех строк, содержащих NA. Я пробовал следующее, но это не работает.
# установка пакетов Примечание# tidyverse устанавливает пакеты для dplyr и ggplot2
install.packages("tidyverse")
install.packages("readxl")
# открыть библиотеку
library(tidyverse)
library(readxl)
setwd("~/Documents/UofL/Data_Science/CECS_635/week_3/")
un <- read_excel("UnitedNations.xlsx")
un1 %>% drop_na(un,)
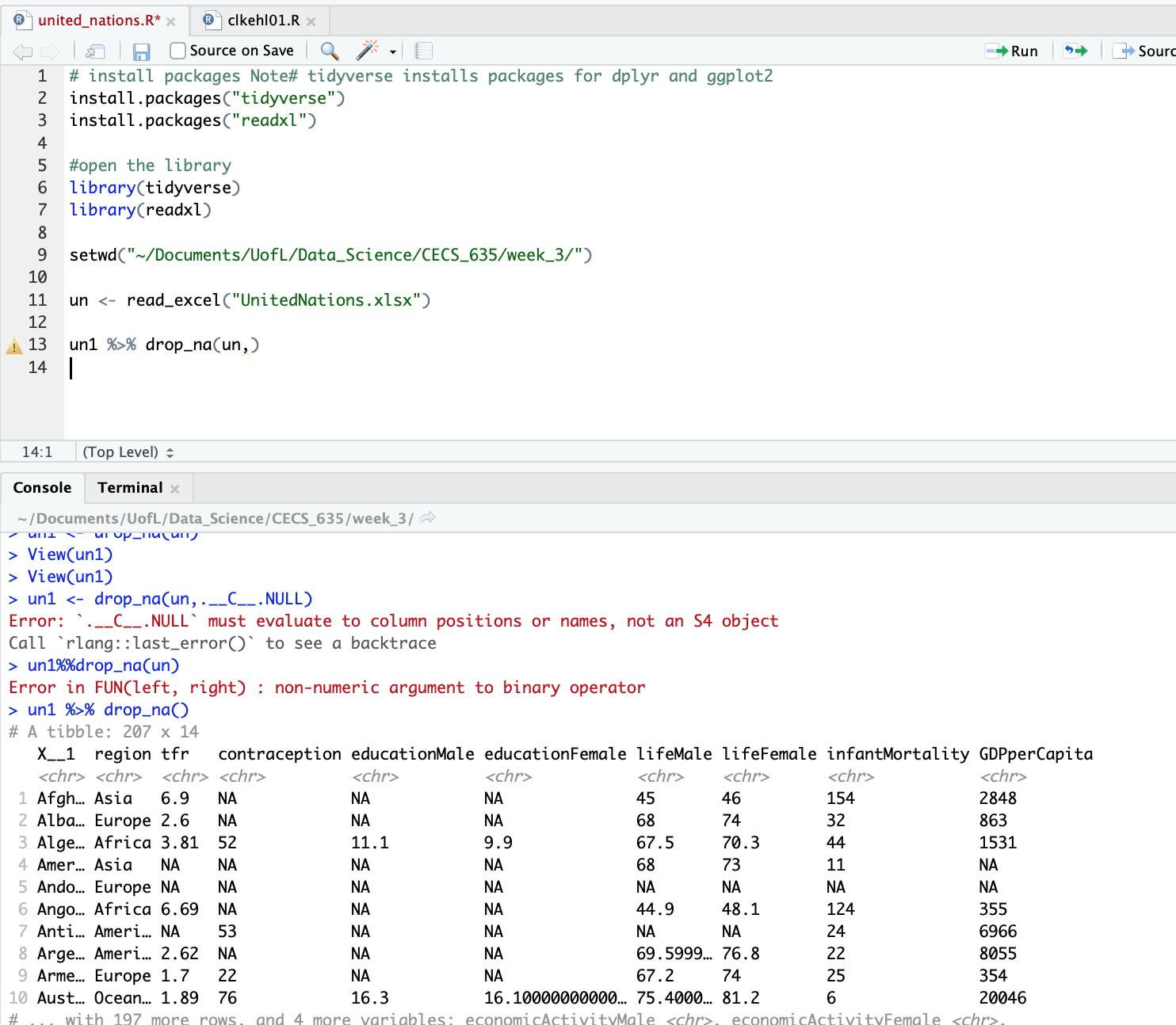
это должно работать
data_set<-na.omit(un)
Если хотите обработать NA как среднее или медиану:
na.mean(un, option = "mean")
Источник:
https://www.rdocumentation.org/packages/imputeTS/versions/2.7/topics/na.mean
Мне удалось удалить значения NA, конвертировав файл xlsx в файл csv. После того как csv был загружен в R, я смог исключить строки NA.
# чтобы удалить значения NA, я конвертировал файл xlsx в csv
united_nations <- read_csv("UnitedNations.csv", col_names = TRUE)
# использовал опцию na.omit для удаления строк с NA
united_nations = na.omit(united_nations)

Или в датафрейме:
mydata <- data.frame(c(1,2,NA,3))
mydata <- mydata[complete.cases(mydata),]
Ответ или решение
Удаление значений NA из импортированного документа XLSX с помощью R
Если вы столкнулись с необходимостью удалить строки с пропущенными значениями (NA) из импортированного документа XLSX в R, дальнейшие шаги помогут вам справиться с этой задачей. В данном ответе мы обсудим процесс, отметим общие ошибки и предложим оптимальные решения.
1. Подготовка окружения
Во-первых, убедитесь, что вы правильно установили и загрузили необходимые библиотеки. Для работы с Excel-файлами и обработкой данных нужно установить пакеты tidyverse и readxl. Вот шаги, которые следует выполнить:
# Установка необходимых пакетов
install.packages("tidyverse")
install.packages("readxl")
# Загрузка библиотек
library(tidyverse)
library(readxl)2. Импорт данных из XLSX
Теперь давайте импортируем ваш файл Excel в R:
setwd("~/Documents/UofL/Data_Science/CECS_635/week_3/") # Укажите путь к вашему файлу
un <- read_excel("UnitedNations.xlsx") # Чтение файла3. Удаление строк с NA значениями
Следующий шаг — это удаление строк, содержащих NA. Используйте функцию drop_na() из пакета tidyverse или na.omit() для достижения этой цели. В вашем исходном коде была ошибка, связанная с неправильным использованием drop_na().
Метод 1: Использование drop_na()
# Убедитесь, что вы используете правильный синтаксис
un_cleaned <- un %>% drop_na() # Удаляем строки с NAМетод 2: Использование na.omit()
Также можно воспользоваться функцией na.omit():
# Удаление NA значений
un_cleaned <- na.omit(un) # Также удаляет строки с NA4. Альтернативные варианты: работа с CSV
Как вы уже упомянули, вы успешно поменяли формат файла с XLSX на CSV, что дало возможность без проблем работать с данными. Вот как это делается:
# Чтение CSV файла
united_nations <- read_csv("UnitedNations.csv", col_names = TRUE)
# Удаление NA значений
united_nations_cleaned <- na.omit(united_nations) # Или use drop_naЭтот метод может быть предпочтительным, если ваш файл XLSX вызывает трудности с импортированием.
5. Удаление NA в датафреймах
Если вы работаете с простыми датафреймами, вы можете использовать complete.cases():
mydata <- data.frame(c(1, 2, NA, 3))
mydata_cleaned <- mydata[complete.cases(mydata), ] # Оставляет только полные случаиЗаключение
Удаление строк с NA значениями в R — это распространенная задача, которую можно решить несколькими способами. Вам нужно всего лишь убедиться, что используете правильные функции и синтаксис. Помните, что работа с документами XLSX может быть менее предсказуемой, чем работа с CSV, поэтому иногда имеет смысл конвертировать файл. Надеюсь, эти советы помогут вам успешно очистить ваш набор данных.
Если у вас возникнут дополнительные вопросы по обработке данных в R, не стесняйтесь их задавать!