Вопрос или проблема
У меня есть задача предсказать бинарную переменную purchase, их датасет сильно несбалансирован (10:100), и модели, которые я пробовал до сих пор (в основном ансамблевые), не справляются. Кроме того, я также пытался применить SMOTE для уменьшения дисбаланса, но результат почти тот же.
Анализируя каждую характеристику в наборе данных, я заметил, что есть некоторые явно видимые различия в распределении характеристик между purchase: 1 и purchase: 0 (см. изображения)
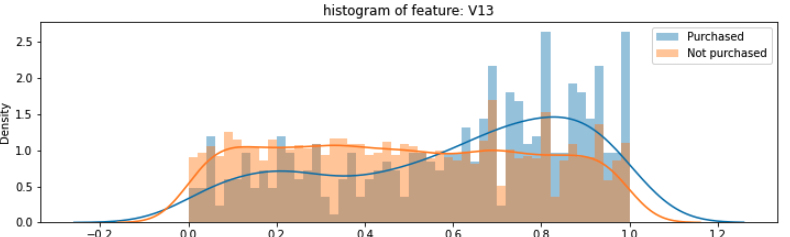
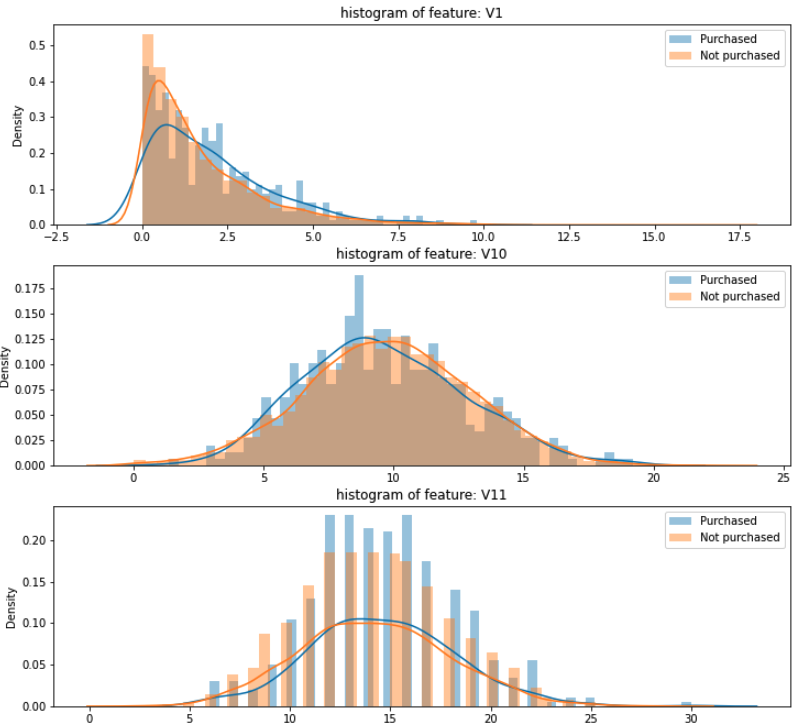
Мой вопрос: как я могу предварительно обработать мой обучающий набор (а также мой набор данных для будущих предсказаний) для того, чтобы сделать эти различия более очевидными для модели?
С другой стороны, является ли это хорошим подходом для работы с сильным дисбалансом классов?
Большое спасибо.
Похоже, что несбалансированный SVM мог бы сработать здесь?
https://scikit-learn.org/stable/auto_examples/svm/plot_separating_hyperplane_unbalanced.html
Смотрев на характеристики, я бы предположил, что rbf kernel более полезен, чем линейный (две из вышеуказанных характеристик выглядят более-менее гауссовыми). Поиск по сетке для нахождения оптимальных параметров тоже мог бы быть полезным здесь.
.
Ответ или решение
Предсказание бинарной переменной, особенно в условиях сильного дисбаланса классов, представляет значительную аналитическую задачу. В вашем случае переменная purchase, имеющая разъем пропорции 10:100, осложняет создание надежной модели. Ниже я предложу подробное руководство, как повысить значимость признаков и улучшить предсказательную способность модели, исходя из анализа распределений признаков.
Анализ признаков
Во-первых, оценка распределений признаков для каждой из категорий (purchase = 1 и purchase = 0) является важной частью вашего исследования. В вашем случае, согласно вашим описаниям, существуют явные различия в распределениях некоторых признаков для этих категорий. Эти различия можно использовать для усиления значимости признаков в модели.
Усиление значимости признаков
-
Нормализация или стандартализация признаков: Расширение характерных особенностей распределений можно добиться с помощью использования нормализации или стандартализации данных. Зачастую это помогает моделям более четко различать существенные разницы между классами.
-
Весовые коэффициенты в Loss-функции: Используйте механизмы изменения весов классов в Loss-функции вашей модели. Это способствует большему вниманию к недостаточно представленным классам в задачах классификации.
-
Feature Engineering: Можно добавлять дополнительные признаки, используя статистические меры (например, среднее, дисперсия), чтобы лучше выделить различия в распределении.
Работа с дисбалансом классов
-
Изменение стратегии тренировки на выборку: Вместо применения методов oversampling, таких как SMOTE, которые, как вы отметили, не дали достижения нужных результатов, попробуйте undersampling или создание ансамблей, справляющихся с дисбалансом, например, Bagging с Random Undersampling.
-
Специализированные алгоритмы: Использование алгоритмов, специально разработанных для работы с дисбалансом данных, таких как unbalanced SVM (как было предложено выше) или Anomaly Detection.
-
Кросс-валидация с учётом баланса: Убедитесь, что кросс-валидация проводится с учётом дисбаланса (Stratified K-Fold Cross-Validation).
Выбор и настройка модели
-
Support Vector Machine (SVM): Ваше предложение SVM с RBF ядром несколько корректно, особенно учитывая, что распределения частично напоминают гауссовские. Проведение Grid Search для нахождения оптимальных гиперпараметров также улучшит результаты.
-
Энсамблирование и устойчивая настройка гиперпараметров: Экспериментируйте с другими ансамблевыми методами. Модели, такие как Random Forest или Gradient Boosting, могут предоставлять механизмы внутреннего регулирования весов классов.
-
Регуляризационные и удельные алгоритмы: Исследуйте использование L1/L2 регуляризаций и алгоритмов, таких как Logistic Regression с соответствующими весами.
Заключение
Надеюсь, данные рекомендации помогут повысить точность вашей модели и сделать различия в распределении признаков более заметными для алгоритмов машинного обучения. Основное внимание уделите предварительной обработке данных и выбору правильного алгоритма, способного справляться с задачей по дисбалансу классов.